Руководство по исследованию скважин
Издание:Наука, Москва, 1995 г., 523 стр., УДК: 622.279.23 (031)+672.323+622.279.5.001.42, ISBN: 5-02-002376-0

В книге рассмотрены техника и технология исследования газовых, газоконденсатных и газонефтяных скважин, методы обработки и интерпретации полученных результатов при стационарных и нестационарных режимах фильтрации с учетом новых разработок по исследованию скважин и в связи с освоением газоконденсато-нефтяных месторождений с высокими пластовыми давлениями и наличием в газе значительного количества кислых компонентов. Большое внимание уделено свойствам газа, нефти, воды и конденсата, режиму эксплуатации скважин и технологиям, позволяющим обеспечить охрану окружающей среды и природных ресурсов, а также качеству определяемых параметров.
Книга представляет интерес для широкого круга специалистов научно-исследовательских институтов, высших учебных заведений и инженерно-технических работников нефтегазовой отрасли.
ТематикаГорючие полезные ископаемые
Все права на материалы принадлежат исключительно их авторам или законным правообладателям. Все материалы предоставляются исключительно для ознакомления. Подробнее об авторских правах читайте здесь!
Внимание! Если Вы хотите поделиться с кем-то материалом c этой страницы, используйте вот эту ссылку:
https://www.geokniga.org/books/9589
Прямые ссылки на файлы работать не будут!
[Почти] Все, что вам нужно знать в 2019 году

Увеличение данных включает в себя процесс создания новых точек данных путем манипулирования исходными данными. Например, для изображений это можно сделать, поворачивая, изменяя размер, обрезая и т. Д.
Этот процесс увеличивает разнообразие данных, доступных для обучения моделей в глубоком обучении, без фактического сбора новых данных. Это, в общем, улучшает производительность моделей глубокого обучения.
В этом руководстве мы рассмотрим несколько статей и исследований, которые были предприняты для решения этой проблемы.
Увеличение случайного стирания данных (2017)
Случайное стирание — это метод увеличения данных, используемый для обучения сверточных нейронных сетей, который включает случайное стирание прямоугольной области изображения. Затем создаются изображения с окклюзиями. Это делает модель устойчивой к окклюзии и снижает вероятность переобучения.

Во время окклюзии структура изображения сохраняется; следовательно, во время увеличения информация не теряется. Пикселям стертых областей повторно присваиваются случайные значения. Этот метод аналогичен применению исключения на уровне изображения. Произвольное стирание не требует изучения параметров, является легким и потребляет мало памяти. Этот метод оценивается на CIFAR-10, CIFAR-100 и Fashion-MNIST.

В этом документе используются архитектуры ResNet, ResNeXt и Wide Residual Networks. Эффективность метода для различных наборов данных показана ниже.

Новейшие достижения в области глубокого обучения — из источника, которому можно доверять. Подпишитесь на еженедельное погружение во все, что связано с глубоким обучением, подготовленное экспертами, работающими в этой области.
AutoAugment: изучение стратегий увеличения на основе данных (CVPR 2019)
AutoAugment — это стратегия дополнения, которая использует алгоритм поиска для поиска политики дополнения, которая даст наилучшие результаты на модели. У каждой политики есть несколько подполитик. Для каждого изображения случайным образом выбирается одна подполитика. Каждая подполитика состоит из функции обработки изображения и вероятности применения этих функций. Операции обработки изображения могут быть перемещением, разрезанием или вращением. Лучшая политика — это та, которая дает наивысшую точность проверки с помощью алгоритма поиска.

Во время экспериментов для алгоритма поиска используется обучение с подкреплением. Изученные политики легко переносятся в новые наборы данных. AutoAugment был протестирован на CIFAR-10, CIFAR-10, CIFAR-100, SVHN, уменьшенный SVHN и ImageNet.
Метод состоит из двух компонентов: алгоритма поиска и области поиска. Алгоритм поиска реализован в виде контроллера RNN. Он выбирает политику увеличения данных, которая содержит информацию об операции обработки изображения и вероятность использования операции в каждом пакете. В нем также есть информация о масштабах операции. Затем эта политика будет использоваться для обучения нейронной сети с фиксированной архитектурой. Полученная при этом точность проверки будет отправлена обратно для обновления контроллера, который обновляется методами градиента политики.

В области поиска политика состоит из 5 подполитик. Каждая подполитика имеет две операции с изображениями, которые применяются последовательно. Каждая операция связана с двумя гиперпараметрами. Это вероятность применения операции и величина операции.

Вот некоторые из результатов, полученных с помощью этого метода:

Быстрое автоулучшение (2019)
Алгоритм Fast AutoAugment находит эффективные политики увеличения, используя стратегию поиска, основанную на сопоставлении плотности. AutoAugment не требует повторного обучения дочерних моделей — вместо этого он ищет политики дополнения, которые максимизируют соответствие между распределением расширенного разделения и распределением другого нерасширенного разделения с помощью одной модели.

Этот метод улучшает производительность обобщения сети за счет изучения политик дополнения, которые обрабатывают расширенные данные как отсутствующие точки данных обучающих данных. Этот метод восстанавливает недостающие точки данных, используя и исследуя семейство дополнений во время вывода посредством байесовской оптимизации на этапе поиска политики.
Вот некоторые результаты, полученные с помощью этого метода:

Изучение стратегий увеличения данных для обнаружения объектов (2019)
Хотя это сама по себе не модельная архитектура, в этом документе предлагается создание преобразований, которые можно применить к наборам данных обнаружения объектов, которые можно перенести в другие наборы данных обнаружения возражений. Преобразования обычно применяются во время обучения.

В этой модели политика дополнения определяется как набор n политик, которые выбираются случайным образом в процессе обучения. Некоторые из операций, которые были применены в этой модели, включают искажение цветовых каналов, геометрическое искажение изображений и искажение только пиксельного содержимого, находящегося в аннотациях ограничивающей рамки.
Эксперименты с набором данных COCO показали, что оптимизация политики увеличения данных может повысить точность обнаружения более чем на +2,3 средней средней точности. Это позволяет единственной модели вывода достичь точности 50,7 средней точности.
SpecAugment: простой метод увеличения данных для автоматического распознавания речи (Interspeech 2019)
SpecAugment — это метод увеличения данных для распознавания речи, который применяется непосредственно к входным параметрам нейронной сети. Он включает в себя деформацию функций, маскирование блоков частотных каналов и маскирование блоков временных шагов. Он используется в задачах сквозного распознавания речи. В LibreSpeech показатель WER составляет 6,8%.

SpecAugment работает с логарифмической спектрограммой входящего звука. Этот метод легко применить в вычислительном отношении, поскольку он непосредственно воздействует на спектрограмму, как если бы это было изображение. Не требует дополнительных данных.
SpecAugment состоит из трех деформаций спектрограммы. Это временная деформация и временная и частотная маскировка. Искажение времени включает в себя деформацию временного ряда во временном направлении. При временной и частотной маскировке маскируется блок последовательных временных шагов или частотных каналов mel. Этот метод позволяет обучать сквозные сети ASR, известные как Listen Attend and Spell (LAS).
EDA: простые методы увеличения данных для повышения производительности при выполнении задач классификации текста (EMNLP-IJCNLP 2019)
EDA состоит из следующих операций: замена синонимов, случайная вставка, случайная замена и случайное удаление.

Замена синонима включает случайный выбор слов, не являющихся стоп-словами, и замену их случайным синонимом. Случайная вставка включает получение случайного синонима случайного слова и вставку этого синонима в случайную позицию в предложении. Произвольный обмен включает случайный выбор двух слов в предложении и смену их местами. Случайное удаление предполагает случайное удаление каждого слова в предложении с определенной вероятностью.
Для экспериментов используются LSTM-RNN и сверточные нейронные сети. Вот полученные результаты:

Неконтролируемое расширение данных для обучения согласованности (2019)
В этой статье предлагается способ добавления шума к немаркированным данным. Качество шума очень важно при обучении без учителя. В статье исследуется внедрение шума при обучении согласованности и определяется, что передовые методы увеличения данных также хорошо работают при полууправляемом обучении. Методы обучения согласованности упорядочивают предсказания модели, чтобы они были инвариантными к небольшому шуму для входных данных или скрытых состояний.
Авторы предлагают заменить традиционные методы инжекции шума на высококачественные методы увеличения данных, чтобы улучшить обучение согласованности. Некоторые из стратегий расширения, используемых в этой статье, — это RandAugment для классификации изображений, обратный перевод для классификации текста и замена Word на TF-IDF для классификации текста. RandAugment не использует поиск, а единообразно использует образцы из одного и того же набора дополнительных преобразований в PIL.

Обратный перевод включает перевод существующего примера с языка A на другой язык B, а затем перевод его обратно на A для получения расширенного образца. Авторы использовали обратный перевод, чтобы перефразировать данные обучения для классификационных текстов.

При замене слов с помощью TF-IDF неинформативные слова с низкими показателями TF-IDF заменяются, а слова с высокими значениями TF-IDF сохраняются.
Вот как работает метод:

Заключение
Теперь мы должны быть в курсе некоторых из наиболее распространенных — и нескольких совсем недавних — методов увеличения данных.
В упомянутых выше статьях / рефератах также есть ссылки на их реализации кода. Мы будем рады увидеть результаты, которые вы получите после их тестирования.
Примечание редактора: Heartbeat — это онлайн-публикация и сообщество, созданное авторами и посвященное предоставлению первоклассных образовательных ресурсов для специалистов по науке о данных, машинному обучению и глубокому обучению. Мы стремимся поддерживать и вдохновлять разработчиков и инженеров из всех слоев общества.
Независимая редакция, Heartbeat спонсируется и публикуется Comet, платформой MLOps, которая позволяет специалистам по обработке данных и группам машинного обучения отслеживать, сравнивать, объяснять и оптимизировать свои эксперименты. Мы платим участникам и не продаем рекламу.
Если вы хотите внести свой вклад, отправляйтесь на наш призыв к участникам. Вы также можете подписаться на наши еженедельные информационные бюллетени (Deep Learning Weekly и Comet Newsletter), присоединиться к нам в » «Slack и подписаться на Comet в Twitter и LinkedIn для получения ресурсов, событий и гораздо больше, что поможет вам быстрее и лучше строить модели машинного обучения.
Ключевые слова являются основой поисковой оптимизации. Поэтому исследование ключевых слов является неотъемлемой частью работ по SEO-продвижению сайта. Существуют различные способы поиска ключевых слов, относящихся к вашей отрасли, бизнесу, продукции или услугам. Во время исследования вы также должны учитывать целевую аудиторию и платформы, которые вы используете для связи с ней.
Существует традиционный или старый метод исследования ключевых слов. Этот процесс можно разбить на четыре этапа. Следующий подход поможет вам найти ключевые слова с высоким объемом поиска, низкой конкуренцией и длинным хвостом ключевых слов.

Четыре этапа исследования ключевых слов
Четыре этапа традиционного исследования ключевых слов — это поиск исходных ключевых слов, вставка исходных ключевых слов, фильтрация возможностей ключевых слов и оценка конкурентоспособности. Эти шаги должны помочь вам найти ключевые слова, на которые вы можете ориентироваться во всем своем содержимом для эффективной поисковой оптимизации.
Ключевые слова, на которые вы нацелились, должны быть использованы для содержания вашего официального сайта, маркетинговых статей и других материалов, которые вы будете использовать для продвижения вашего бизнеса в Интернете.
Для этого исследования вы можете использовать бесплатный инструмент, такой как Планировщик ключевых слов Google Рекламы или Яндекс Директ. Вы также можете изучить платные инструменты для поиска ключевых слов.
Первый шаг поиска исходных ключевых слов заключается в использовании различных методов для составления списка потенциальных ключевых слов. Этот шаг включает в себя изучение конкурентов.
Второй шаг — добавить исходные ключевые слова из короткого списка, чтобы создать гораздо больший список фраз и слов. Это ваши возможности ключевых слов.
Третий шаг — отфильтровать эти возможности ключевых слов на основе объема поиска в месяц и других данных поисковой оптимизации.
Четвертый и последний шаг — оценить конкурентоспособность или силу всех ключевых слов, которые вы собираетесь использовать. Ключевые слова должны оцениваться на основе метрики сложности и анализа поисковой выдачи.
Найти исходные ключевые слова
Исходные ключевые слова можно придумать без использования какого-либо инструмента, поскольку вы можете придумать релевантные термины для своих продуктов, услуг или бизнеса. Эти ключевые слова не обязательно должны быть идеальными. Они просто создают основу для последующих и более конкретных исследований. Составьте список исходных ключевых слов, а затем используйте соответствующие инструменты, чтобы узнать о них больше информации.
Вы можете использовать различные платные инструменты для получения поисковых предложений. Это кропотливо долгий процесс, а также утомительный. Также важно использовать вопросы для поиска исходных ключевых слов, например общие вопросы, такие как что, как, где, что и когда, чтобы придумать множество идей для ваших исходных ключевых слов.
Если вы занимаетесь товарным направлением, то отличными источниками коммерческих ключевых слов могут стать топовые маркетплейсы. У вас могут быть отличные идеи для исходных ключевых слов. Посетите форумы и доски объявлений, наиболее актуальные для вашего бизнеса.
Исследование ключевых слов
Это простой шаг. Возьмите инструмент исследования ключевых слов и введите в него начальные ключевые слова. Если у вас всего несколько ключевых слов, вы можете ввести их вручную. Если у вас длинный список начальных ключевых слов, вы можете импортировать его в Keyword Planner от Google. Вы получите обширный список ключевых слов для начальных ключевых слов. Весь список ключевых слов может быть не полностью релевантным. В нем будут ключевые слова, которые будут в некоторой степени релевантными.
Фильтрация ключевых слов
Это важный шаг, поскольку вы удаляете нерелевантные или полурелевантные ключевые слова, чтобы сосредоточиться на наиболее важных. Вы по-прежнему можете использовать бесплатный инструмент или некоторое программное обеспечение премиум-класса. У этого шага есть конкретные цели. Вы должны отдавать приоритет высокому объему поиска в релевантности ниши, обеспечивая при этом низкую конкуренцию ключевых слов.
Релевантность ниши заключается в исключении ключевых слов, которые относятся к чему-то общему, в то время как вы фокусируетесь на чем-то более конкретном. Когда у вас есть исходные ключевые слова и вы подключаете их, у вас будут связанные ключевые слова. Удаление ключевого слова, которое лучше всего описывает вашу нишу, приведет к полурелевантным, а в некоторых случаях и нерелевантным ключевым словам. Вы должны определить приоритет ключевого слова, которое лучше всего подходит для вашей ниши, и отфильтровать ключевые слова на этой основе. Исключите ключевые слова, в которых используются другие полурелевантные слова или фразы, которые далеки от вашей ниши или совершенно не связаны с ней.
Вы должны оценить объем поиска по отфильтрованным ключевым словам. Не беспокойтесь об объеме поиска ключевых слов, которые вы не собираетесь использовать, и тех, которые не так важны. Инструменты исследования ключевых слов позволят вам фильтровать результаты в соответствии с ежемесячными объемами поиска. Только несколько инструментов являются точными, поэтому вы должны выбрать надежный. Вы также должны иметь возможность легко экспортировать данные в электронную таблицу. Убедитесь, что ваши отфильтрованные ключевые слова имеют низкую конкуренцию. Вы можете сделать это, оценив сложность ключевого слова. На самом деле это четвертый шаг, поскольку в этом сложном процессе есть некоторые проблемы.
Оценка сложности и конкурентоспособности ключевых слов
Анализ поисковой выдачи играет решающую роль на этом этапе. Вам нужно знать, какие ключевые слова используются в поиске и создают достаточную привлекательность в контексте трафика, но не являются целевыми для всех и каждого. Вам нужна низкая конкурентоспособность, чтобы вы могли блистать своим контентом, оптимизированным для выбранных ключевых слов. Для этого упражнения вы можете использовать бесплатные инструменты или платное программное обеспечение.
Бесплатные инструменты не идеальны для анализа поисковой выдачи. Проблема с Планировщиком ключевых слов Google заключается в том, что он фокусируется на ключевых словах, используемых рекламодателями. Их целевой рынок состоит из рекламодателей, но вам нужно выяснить конкурентоспособность для органических результатов поисковой системы. Ваша цель — поисковая оптимизация, а не реклама с оплатой за клик или рекламные посты по выбранным ключевым словам. Есть и другие бесплатные инструменты, но они не совсем надежны. Вам нужно много данных, и информация должна быть точной.
Существует множество платных инструментов анализа SERP. Попробуйте сравнить их и использовать самый надежный инструмент. Отдайте предпочтение объему данных, точности и актуальности для вашей ниши. Вам нужен инструмент, чтобы предоставить вам доступ к обширным данным поисковой оптимизации.

Последнее слово об исследовании ключевых слов
Не существует единого способа проведения исследования ключевых слов. В данном руководстве рассказывается о традиционном подходе. Существует выбор между бесплатными и платными инструментами. У вас может быть свой собственный взгляд на релевантные ключевые слова. Не всегда инструмент выдает наиболее релевантные ключевые слова.
Пользователи влияют на данные, собираемые различными инструментами. Если вы сможете заметить тенденции или даже задать их, тогда вы сможете стать победителем со своей уникальной стратегией контент-маркетинга. В этом гораздо меньше уверенности, чем в подходе, который полагается на имеющиеся данные.
Исследование ключевых слов — это не одноразовое упражнение. Поисковая оптимизация — это многолетний процесс, так же как и исследование ключевых слов.
Объем поиска, конкурентоспособность и даже релевантность ключевых слов время от времени меняются. Ключевое слово, идеально подходящее для данной ниши, всегда будет оставаться актуальным, но то, как люди ищут соответствующую информацию, будет меняться, и это необходимо учитывать как можно скорее.
Содержание всегда должно быть оптимизировано для настоящего и будущего. Вам также следует рассмотреть возможность использования органического рейтинга конкурентов, чтобы выбрать заранее подготовленные ключевые слова.
Если вам нужна помощь в сборе необходимой семантики (списка ключевых слов), то не стесняйтесь прийти на консультацию.
Успехов вам,
Александр Тригуб
В общем и целом

Малыш-дрон делает исследования с:
Основные задачи научно-исследовательского отдела (или НИО), или отдела исследований и разработок, или Research and Development (сокращенно R&D или RnD) — предоставлять улучшения различной аппаратуры на станции, принимать участие в выполнении целей станции, обеспечивать экипаж лучшим инструментарием и расширять возможность робототехнического отдела посредством повышения уровней исследования.
Для выполнения обязанностей научно-исследовательского отдела вам необходимо создавать и разбирать различные предметы в целях повышения уровней исследований, дающих доступ к более сложным и мощным устройствам.
Для открытия некоторых устройств вам потребуется повышение уровней
- Исследований токсинов, проводящихся на полигоне токсинов (см. руководство по токсикологии);
- Исследований нелегальных технологий посредством разбора предметов Синдиката;
- Исследования инопланетных технологий посредством разбора снаряжения абдукторов.
Консоль НИО
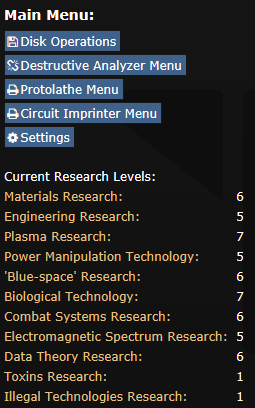
консоль используется для работы со всей относящейся к отделу аппаратурой
Она предоставляет доступ к
- Операциям с дисками
- Меню деструктивного анализатора
- Меню протолата
- Меню принтера плат
- Настройке синхронизации
- Списку отраслей исследований и их уровней
 Разбор
Разбор
 Разбор
Разбор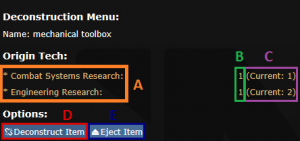
Консоль может также предоставить краткую информацию об уровнях исследований
A — отрасль исследований
B — уровень исследований, предоставляемый предметом
C — уровень исследований, сохраненный в базе данных
Деструктивный анализатор позволяет разбирать предметы, чтобы повысить уровни исследований посредством консоли и разблокировать лучшие технологии для протолата и принтера плат.
Процесс разбора
- Поместите разбираемый предмет в анализатор.
- Воспользуйтесь консолью и нажмите
Deconstructive Analyzer Menu. - Нажмите
Deconstruct Item, чтобы разобрать предмет, илиEject Item, чтобы его извлечь.
Повышение уровней исследований
- При разборе предмета уровень исследований повышается до значения, предоставляемого предметом.
- В случае если уровень исследований, предоставляемый предметом, равен уровню исследований в базе данных, значение уровня повышается на 1.
Во втором случае предполагается, что вы будете разбирать предметы, созданные на повышенных уровнях исследований.
В качестве исключения вам могут послужить технические записи, купленные у торговцев ТСФ и предоставляющие занебесные уровни исследований.
Базовые исследования (до уровня 5) могут быть достигнуты посредством разбора предметов, созданных в протолате и принтере плат, в то время, как для достижения продвинутых исследований (выше уровня 5) вам придется прибегнуть к помощи других отделов (в частности, ксенобиологии и робототехники).
В списке разбора для исследований для вас предоставлен некий алгоритм разбора для достижения базовых и продвинутых исследований. Однако, тем не менее, данный алгоритм не является настолько эффективным, и может потребоваться небольшое экспериментирование для собственных наработок.
Этот алгоритм относится к процессу непосредственно проведения исследований для повышения уровней.
Также вам предоставляется небольшой инструмент для симуляции процесса разбора предметов. При нажатии кнопки filter будут показываться предметы, разбор которых повысит уровень конкретной отрасли исследований.
Протолат
 Протолат
Протолат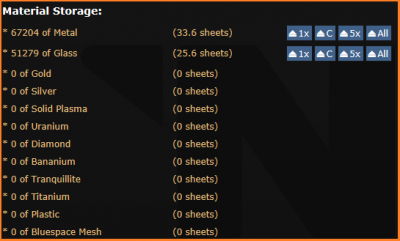
В зависимости от количества материалов в протолате, вы можете создать один, пять или десять предметов за раз.
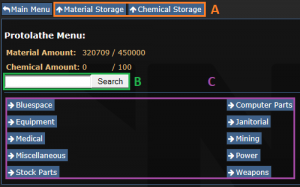
A — Хранилище материалов и химикатов соответственно (позволяет извлекать их из протолата в различных количествах)
B — Строка поиска (для конкретных предметов)
C — Категории предметов
![]()
Если вы нашли конкретный предмет, то вот, как будет выглядеть результат поиска:
A — Наименование предмета
B — Требуемые материалы
C — Недостающие материалы
Протолат позволяет создавать большое множество предметов, как, например, блюспейсовые устройства, медицинские инструменты и импланты, компоненты для любого вида аппаратуры и вооружение.
Как и в автолате, изначально в нем доступны для создания самые базовые предметы, которые затем могут быть разобраны для повышения уровней исследований.
Чем более продвинутые предметы, тем более высокие уровни исследований и тем большее количество и разнообразие материалов требуются для их создания (что делает вас зависимыми от шахтёров).
Принтер плат

Принтер плат позволяет вам печатать множество микросхем для различной аппаратуры и консолей на станции. (чтобы увидеть полный список — сюда)
Принцип работы абсолютно аналогичен протолату, однако для создания плат в основном требуется стекло и, в некоторых случаях, металл, золото или алмазы.
Синхронизация

В целом, все кнопки в меню настроек говорят сами за себя, что они обозначают.
Синхронизация исследований — важнейшая часть работы вашего отдела, — вы синхронизируете исследования с сервером и создаёте на нём резервную копию.
При синхронизации на сервере и на консоли сохраняются наиболее высокие достигнутые уровни исследований. Вы сможете загрузить бэкап с сервера на новую консоль, если старая, допустим, оказалась разбита.
Робототехники также могут загрузить синхронизированные исследования на свою консоль, так как исследования в не меньшей мере необходимы в их работе, поскольку они предоставляют им более продвинутые технологии для создания в фабрикаторе.
Аналогично, механик может загрузить синхронизированные исследования на свою консоль, для создания более продвинутых деталей в фабрикаторе челноков.
Помимо того, директор исследований с помощью своей консоли управления сервером может предоставлять исследования на другие консоли на станции или же наоборот — удалять их.
Для синхронизации просто нажмите на кнопку Settings на своей консоли.
Улучшения
Улучшение — процесс замены составных компонентов аппаратуры их более продвинутыми версиями, как, например, замена микроманипулятора фемтоманипулятором.
Помимо основных компонентов, в состав аппаратуры могут входить пробирки, провода, материалы и запальники, у которых нет более продвинутых версий.
Замена на улучшенные компоненты в машине улучшает ее возможности, а в некоторых случаях позволяет ей выполнять новые функции (подробнее — Руководство по продвинутому строительству).
Доступны три метода замены на улучшенные компоненты в порядке от худшего к лучшему:
 Реконструкция машины
Реконструкция машины
- Отвёрткой открутите панель машины.
- Ломом разберите машину
- Заново вставьте плату в машину
- Вставьте новые улучшенные компоненты
- Отвёрткой соберите машину
Хотя этот метод самый долгий, все нестандартные компоненты могут быть заменены только с помощью этого метода.
Однако он также сбрасывает машину и выбрасывает все материалы, хранящиеся в машине, что может привести к потере некоторых материалов, например половины алмазов.
Быстрозаменитель компонентов
Он же БЗК (RPED — Rapid Part Exchange Device)
- Напечатайте БЗК на протолате.
- Вставьте новые компоненты в БЗК (вы можете просто использовать его на плитку с кучей компонентов и они все загрузятся в БЗК).
- Отвёрткой открутите панель машины.
- Примените (ЛКМ) БЗК на машине для замены компонентов (может потребоваться несколько применений, если есть несколько лучших компонентов одного типа).
- Прикрутите панель обратно отвёрткой.
Замена происходит мгновенно.
С другой стороны, БЗК может быть напечатан только с определённым уровнем исследований и может хранить только стандартные компоненты.
В дополнение к этому, предел хранения компонентов ограничен, и использование этого метода сбрасывает настройки машины, как в шаге реконструкции. В случае оборудования R&D, машины необходимо повторно подключить к консоли.
Блюспейсовый быстрозаменитель компонентов
Он же ББЗК (BRPED — Bluespace Rapid Part Exchange Device)
- Напечатайте ББЗК на протолате.
- Вставьте новые компоненты в ББЗК (вы можете просто использовать его на плитку с кучей компонентов и они все загрузятся в ББЗК).
- Примените (ЛКМ) ББЗК на машине для замены компонентов (может потребоваться несколько применений, если есть несколько лучших компонентов одного типа).
Замена происходит мгновенно и может выполняться удалённо.
Однако ББЗК может быть напечатан только с определённым уровнем исследований и может хранить только стандартные компоненты.
Его предел хранения компонентов намного больше, чем у БЗК, и использование ББЗК не приводит к сбросу конфигураций.
Диск для хранения технологий

Диски для хранения технологических данных используются для хранения уровней исследований на физическом диске. Их можно использовать для:
- Передачи уровней исследований между различными устройствами (необходимо для передачи исследований токсинов с тахионно-доплеровского массива на консоль R&D)
- Выполнения вашей рабочей задачи (отправив диски на грузовом шаттле на ЦК)
Скачивание технологий на диск
В сравнении с пустым диском вы теперь можете не только извлечь его, но и:
- Загрузить исследование в базу данных
- Очистить диск для копирования новой информации.
Диск для хранения дизайнов
Диски для хранения дизайнов используется для передачи способа изготовления предмета на другие устройства.
Их можно загрузить на автолат ![]() или на другую консоль R&D.
или на другую консоль R&D.
Каждый диск также будет давать 25 очков в карго.
Для загрузки технологий на диск нужно повторить те же действия что и с технологиями:
- Вставьте диск в консоль R&D
- Выберите пункт
Disk Operations - Нажмите кнопку
Load Design to Disk - Выберите вещь, которую вы хотите копировать.
На автолате можно производить лишь вещи из металла и стекла, поэтому перенести производство полностью не получится.
Однако производство на автолате будет выгоднее в 3,2 раза (при максимальных улучшениях).
Полный список переносимых предметов.
Сделайте в бриге завод по производству МЩ.
Обезвреживание аномалий
Иногда на борту станции могут появляться аномалии различной природы, такие, как:
| Название | Внешний вид | Воздействие | Дестабилизация |
|---|---|---|---|
|
Атмосферная (Atmospheric) |
Скопление дыма размером в одну плитку. | Постепенно повышает температуру в помещении и выделяет некоторое количество горючей плазмы. | Если оставить её без внимания, она может спровоцировать взрыв на внушительной площади и создать разгерметизацию. Помимо неё самой, на её месте также может появиться красный или оранжевый слайм. |
|
Блюспейсовая (Bluespace) |
Высокоинтенсивное скопление блюспейс-энергии голубого цвета с разрядами, радиально расходящимися от эпицентра. | Любой предмет или гуманоид, контактирующий с аномалией, случайным образом телепортируется. | При достижении нестабильности аномалия вызывает дислоцирование также случайным образом группы объектов в районе своего последнего местоположения, а затем исчезает. |
|
Воронка (Vortex) |
Небольшой гибрид червоточины и сингулярности. | Способна нанести значительные структурные повреждения на относительно большой площади. В отличие от непосредственно сингулярности, она не втягивает предметы в себя. | С этой аномалией бороться крайне тяжело, а к тому моменту, когда вы найдете скафандр и доберетесь до неё, она уже может исчезнуть. |
|
Гравитационная (Gravitational) |
Пульсирующее сферическое образование синего цвета, притягивающее к себе все незакреплённые предметы, включая гуманоидов. | При контакте с этой аномалией гуманоид будет отброшен от неё на некоторое расстояние из-за гравитационных возмущений на её поверхности. | Просто исчезает. |
|
Поточная (Flux) |
Высокоинтенсивное скопление энергии золотого цвета с разрядами, радиально расходящимися от эпицентра. | TODO | Спровоцирует относительно небольшой взрыв. |
Через некоторое время после появления аномалии на борту будет выведено оповещение об её обнаружении в конкретной локации. Вам, как учёному, необходимо вовремя добраться туда и обезвредить её, чтобы предотвратить любой возможный ущерб и заполучить вожделенное ядро аномалии.
Для обезвреживания аномалии вам необходимы анализатор и сигналер, или [КПК] с сигнальным картриджем (Signal A.C.E.), которым стандартно снаряжены все учёные.
Приблизьтесь к аномалии и тыкните по ней анализатором, он просканирует аномалию и скажет вам ее частоту и код (например, 145.7:22). Затем возьмите сигналер или КПК с сигнальным картриджем (Signal A.C.E.), установите выведенные вам частоту и код аномалии и пошлите по ним сигнал. Через секунду аномалия схлопнется, оставив после себя облако пара и своё ядро.
Ядра обладают высокой научной ценностью и позволяют повысить уровень конкретной отрасли исследований выше 7 уровня (в зависимости от природы аномалии, из которой было добыто ядро). Ядро блюспейс-аномалии будет ценно как для вас, так и для робототехников — оно применяется при создании экзокостюма «Фазон», который обладает особой функцией фазового перехода и способен перемещаться сквозь препятствия.
Любовное письмо для R&D
Исследование и разработка — одна из самых утомительных и монотонных работ на станции.
Поэтому вот несколько идей, как сделать ваше пребывание в отделе R&D более приятным для себя и других:
- Более активно выдавайте предметы по запросу экипажа.
- Не только улучшайте, но и создавайте свои собственные машины.
- Сделайте перепланировку в отделе.
- Создайте сеть телепортов, — разместите несколько квантовых платформ.
- Создайте резервную сеть телекоммуникаций.
- Экспериментируйте с предметами, создаваемыми в R&D.
Поскольку отдел исследований и разработок может построить большую часть оборудования на станции, вы также можете перепроектировать и улучшить само R&D.
Безумный ученый
R&D может создавать одно из лучших оборудований на станции, позволяя использовать новейшие инструменты, импланты и даже оружие. Если у вас есть эмаг, вы можете взламывать ящики, требующие более высокого доступа, и получать их содержимое.
Имейте в виду, хотя печать челюстей жизни или лучших корпусов для гранат не вызовет подозрений, могут возникнуть вопросы, если кто-то случайно увидит, как вы кладете в карман портативный монитор экипажа.
Более того, вы можете построить практически любую консоль и машину, которые есть на станции, что позволяет скрытно саботировать станцию и создать все, что могут создать другие отделы.
Проведение исследований — это один из способов, с помощью которого многие люди и компании находят информацию, необходимую им для решения проблем, ответов на вопросы и принятия решений. Вторичное исследование — это метод поиска данных, собранных другими, чтобы быстрее найти полезную информацию. Понимание того, как проводить вторичные исследования, может помочь вам найти полезные ответы, когда у вас ограниченное время или небольшой бюджет. В этой статье мы даем определение вторичному исследованию, перечисляем примеры вторичных источников, описываем, как его проводить, и перечисляем его преимущества и недостатки.
Что такое вторичное исследование?
Вторичные исследования — это информация, статистика и другие данные, которые первичные исследователи уже изучили и задокументировали. Вторичные исследования не генерируют никаких новых данных. Вместо этого вторичные исследователи часто собирают данные из нескольких источников, обобщают их и реорганизуют в новые документы. Это делает данные более доступными для тех, кто хочет использовать их в образовательных или деловых целях.
Первичное исследование против вторичного исследования
Первичные и вторичные исследования имеют свои цели, способы использования и методы. Хотя оба они пытаются ответить на вопрос, два типа исследований идут разными путями. Некоторые из самых больших различий между первичными и вторичными исследованиями включают:
Источники
В первичных исследованиях используются оригинальные источники для получения новых данных для публикации. Это данные, которые они собирают сами, находя рассказы из первых рук или проводя наблюдения. Исследователи могут найти свои данные с помощью таких методов, как проведение интервью, руководство фокус-группами, проведение опросов или сбор и анализ данных.
Вторичные исследования обычно используют данные, опубликованные первичными исследователями в качестве основного источника информации. Это могут быть опубликованные объемы исследований рынка, результаты поиска в Интернете или университетские и государственные архивы. Хотя вторичные исследования часто включают сравнение нескольких источников для выработки собственных выводов, они основаны на выводах первичных исследователей.
Цели
Первичные исследователи надеются найти ответы на вопросы и решения нерешенных проблем. Данные для ответа на эти вопросы, как правило, недоступны или неполны, а это означает, что им необходимо провести собственное исследование для сбора данных и информации.
Вторичный исследователь также ищет ответ на вопрос или проблему. Тем не менее, есть надежда, что вопрос достаточно распространен, чтобы исследования и данные уже существовали. Это связано с тем, что основная цель вторичных исследователей — быстро и легко обучить себя и свою организацию, что может быть полезно, когда у вас ограниченное время или меньший бюджет.
Участие исследователя
Первичное исследование часто требует от исследователя прямого контакта с изучаемыми предметами, потому что они обычно проводят исследование самостоятельно. Первичные исследователи также могут нанять фирму или внешний источник для проведения исследования от их имени.
Вторичное исследование часто менее вовлечено, потому что исследователь обычно организует и изучает ранее опубликованные работы, чтобы найти необходимую информацию. Это означает, что вторичное исследование обычно выполняется быстрее и проще.
Расходы
Первичное исследование обычно включает в себя затраты на опрос источников и сбор данных. Сюда также могут входить дорожные расходы, связанные с отправкой исследователей в поле или наймом фирмы для проведения исследования. Поскольку это исследование уже завершено, вторичные исследования могут стоить очень мало. Если данные доступны бесплатно в Интернете, некоторые вторичные исследования могут ничего не стоить, и вы часто можете проводить их из своего дома или офиса. Из-за этого некоторые называют это «кабинетным исследованием».
Вторичные методы исследования
Методы проведения вторичного исследования обычно включают поиск и изучение опубликованных исследований. Это можно сделать несколькими способами, в том числе:
-
Поиск данных в Интернете. Существует множество веб-сайтов, посвященных исследованиям рынка, а также блоги и другие веб-сайты, посвященные анализу данных. Некоторые из них бесплатны, хотя некоторые взимают плату.
-
Поиск данных, опубликованных образовательными учреждениями: многие учреждения проводят тщательные и заслуживающие доверия исследования, а некоторые позволяют запросам предприятий просматривать или использовать свои данные.
-
Поиск опубликованных данных в библиотеках. Некоторые библиотеки содержат опубликованные данные государственных учреждений, учебных заведений и других исследователей рынка. Хотя ресурсы различаются в зависимости от библиотеки, данные могут быть бесплатными и надежными.
-
Поиск в архивах данных, принадлежащих различным агентствам. Многие государственные учреждения хранят коллекции собственных исследований. Как правило, для поиска в их архивах требуется официальный запрос, а иногда даже надзор при поиске. Однако данные могут быть очень точными.
Примеры вторичного исследования
Есть много видов вторичных исследований. Многие из них представляют собой онлайн-документы или опубликованные работы, например книги. Некоторые из наиболее распространенных примеров вторичного исследования включают:
-
Учебники
-
Новостные статьи
-
Исследования, опубликованные университетом
-
Энциклопедии
-
Опубликованное исследование рынка
-
Академические журналы
-
Опубликованные демографические исследования
-
Правительственные записи
Как проводить вторичное исследование
Попытка выполнить следующие шаги для проведения вторичного исследования:
1. Установите свою тему
При проведении исследования у вас, вероятно, возникает вопрос или проблема, которую необходимо решить. Знание конкретного типа информации, которая вам нужна, может помочь вам быстрее найти ответы. Например, если ваша компания производит карандаши, вы можете захотеть узнать, сколько материала вам нужно на год.
2. Соберите данные
После того, как вы определились с темой исследования, вы можете приступить к определению потенциальных источников исследования. Обычно вы можете найти множество источников в Интернете, большинство из которых находятся в свободном доступе. Подумайте о том, чтобы сравнить цены и отзывы пользователей, чтобы определить, какие ресурсы для исследования рынка могут оказаться для вас наиболее полезными. Например, для компании по производству карандашей поиск в Интернете может показать несколько вариантов, в которых перечислены данные о продажах карандашей.
3. Сравните данные из нескольких источников
В зависимости от временных рамок, ресурсов и условий первичного исследования каждый источник может немного отличаться. Собирая данные из нескольких источников, вы можете сравнить данные из каждого, чтобы лучше понять, что вы собрали. Для компании по производству карандашей вы можете сравнить данные более крупных и мелких компаний, чтобы найти среднее количество используемых материалов. Вы также можете отслеживать использование и продажи материалов с течением времени, чтобы лучше подготовиться к тому, сколько материалов вам может понадобиться в течение года.
4. Проанализируйте свои выводы
После того, как вы сравнили все данные, вы можете проанализировать то, что вы нашли. Существует несколько способов анализа данных, в том числе:
-
Распознавание тенденций и закономерностей для прогнозирования изменений
-
Поиск выбросов в данных, которые помогут вам подготовиться к неожиданным результатам
-
Сравнение с опытом работы в вашей собственной компании
-
Выявление любых переменных, которые могут повлиять на данные
Анализируя свои выводы, вы можете определить, поможет ли собранная вами информация ответить на ваш вопрос. Если вам нужны дополнительные данные, вы можете продолжить исследование, пока не найдете нужный ответ.
Преимущества вторичного исследования
Вторичное исследование может иметь много преимуществ, и их понимание важно для определения того, когда оно будет наиболее полезным для вас. Принимая решение о проведении вторичного исследования, учитывайте следующие преимущества:
-
Это может быть менее затратным и трудоемким
-
Может быть много доступных данных
-
Наблюдение за тем, как другие использовали то же доступное исследование, может помочь вам определить, полезно ли оно для ваших нужд.
-
Вы можете сравнить несколько источников в дополнение к текущим тенденциям
-
Вы можете найти опубликованные документы, которые объясняют, как другие уже использовали данные и были ли они им полезны.
Недостатки вторичного исследования
Вторичное исследование может иметь некоторые недостатки. Полезно понимать эти недостатки, чтобы понять, как избежать потенциальных проблем. Некоторые недостатки вторичного исследования включают:
-
Подлинность первичного исследования не всегда сразу очевидна
-
Первичные исследования не всегда используют текущие данные
-
Это зависит от качества первичного исследования
-
Данные могут не относиться к вашей проблеме
Чтобы определить, полезен ли первоисточник, вы можете сначала выяснить, какие источники обычно наиболее точны и полезны для других. Это может сэкономить ваше время, определив, какие источники с наибольшей вероятностью предоставят вам нужные данные.