Одна из самых неприятных ситуаций, с которой может столкнуться пользователь при работе в Microsoft Excel — это поиск и подстановка данных с неточным совпадением. Когда вам надо подставить данные из одной таблицы в другую, но вы при этом уверены, что в обеих таблицах совпадающие элементы называются одинаково, то проблем нет — к вашим услугам множество способов: функции ВПР и её аналоги, надстройка Power Query и т.д.
А вот если в одной таблице «Пупкин Василий», а в другой просто «Пупкин», или «Пупкин В.», или даже «Пупкен», то все эти красивые способы не работают. Причем на практике такое встречается постоянно, особенно с почтовыми адресами или названиями компаний:

Обратите внимание на различные типы несоответствий, которые могут встречаться:
- переставлены местами улица, город, дом
- отсутствует какая-то часть адреса или, наоборот, есть что-то лишнее (индекс, номер квартиры)
- по-разному записан город (с буквой «г.» или без) или улица
- опечатки и ошибки (Козань вместо Казань)
Про точное соответствие или даже поиск по маске тут говорить не приходится. Помочь в таком случае могут только специальные макросы или надстройки для Excel. Про одну из таких макро-функций на VBA я уже писал, а здесь хочется рассказать про еще один вариант решения подобной задачи — надстройку Fuzzy Lookup от компании Microsoft.
Эта надстройка существует с 2011 года и совершенно бесплатно скачивается с сайта Microsoft. Системные требования: Windows 7 или новее, Office 2007 или новее, соответственно. После установки у вас в Excel появляется одноименная вкладка с единственной кнопкой на ней:

Нажатие на эту кнопку включает специальную панель в правой части окна Excel, где и задаются все настройки поиска:

Сразу хочу отметить, что эта надстройка умеет работать только с умными таблицами, поэтому все исходные таблицы нужно конвертировать в умные с помощью сочетания Ctrl+T или кнопки Форматировать как таблицу на вкладке Главная (Home — Format as Table):
Алгоритм действий при работе с надстройкой Fuzzy Lookup следующий:
- Выберите какие таблицы нужно связать в выпадающих списках Left и Right Table.
- Выберите ключевые столбцы в левой и правой таблицах, по которым нужно проверить соответствие и нажмите кнопку для добавления созданной пары в список Match Columns
- В списке Output Columns отметьте галочками столбцы, которые вы хотите получить на выходе в качестве результата.
- Установите активную ячейку в пустое место на листе, куда вы хотите вывести данные
- Нажмите кнопку Go
После анализа мы получаем таблицу, где каждому элементу ключевого столбца из первой таблицы подобрано максимально похожее значение из второй:

Лепота!
Нюансы и подводные камни
- Точность подбора можно регулировать с помощью ползунка Similarity Threshold в нижней части панели Fuzzy Lookup. Чем правее его положение, тем строже будет поиск, и — как следствие — тем меньше результатов надстройка будет находить. Если сдвинуть его влево, то результатов станет больше, но возрастет риск ошибочного совпадения. Тут все зависит от вашей конкретной ситуации — экспериментируйте.
- На больших таблицах поиск может занимать приличное количество времени (до нескольких десятков секунд), хотя многое, конечно, зависит от мощности вашего компьютера. Как вариант, для ускорения в настройках (кнопка Configure в нижней части панели) можно попробовать включить параметр UseApproximateIndexing в разделе Global Settings.
- Перед нажатием на кнопку Go не забудьте выделить пустую ячейку, начиная с которой вы хотите вывести результаты. Если случайно вы оставите активную ячейку где-нибудь в исходных данных, то надстройка выведет итоговую таблицу прямо поверх них, и вы их потеряете. Причем отмена последнего действия будет невозможна, а кнопка Undo в нижней части панели не всегда срабатывает почему-то.
- Для вывода столбца с коэффициентом подобия FuzzyLookup.Similarity необходимо, чтобы у вашего Excel была точка в качестве десятичного разделителя (целой и дробной части). Если это не так, то эту настройку временно можно поменять через Файл — Параметры — Дополнительно (File — Options — Advanced).
- Fuzzy Lookup — это не обычная надстройка, написанная на VBA (как мой PLEX, например), а COM-надстройка. Разница в том, что она устанавливается как отдельная программа, т.е. вам нужны соответствующие права на установку ПО на вашем компьютере. Дома, ясное дело, проблем не будет, а вот многим корпоративным пользователям, скорее всего, придется обращаться к вашим айтишникам. После установки отключать и подключать ее в дальнейшем можно на вкладке Разработчик — Надстройки COM (Developer — COM Add-ins).
В любом случае, при всех имеющихся минусах, эта надстройка однозначно стоит того, чтобы находиться в арсенале любого продвинутого пользователя Microsoft Excel.
Ссылки по теме
- Неточный поиск ближайшего похожего текста с помощью макрофункции
- Анализ текста регулярными выражениями (RegExp) в Excel
- Ссылка на скачивание надстройки Fuzzy Lookup с сайта Microsoft
Содержание
- Как применить нечеткий поиск, чтобы найти примерный результат совпадения в Excel?
- Нечеткий поиск путем поиска и замены
- Нечеткий поиск одного значения или нескольких значений с помощью удобного инструмента
- Быстрое разделение данных на несколько листов на основе столбца или фиксированных строк в Excel
- Образец файла
- Другие операции (статьи)
- Нечёткий текстовый поиск в Power Query
- Шаг 1. Грузим исходные данные в Power Query
- Шаг 2. Выполняем объединение
- Шаг 3. Пишем свою М-функцию подобия
- P.S. А у меня в Excel такого нет!
Как применить нечеткий поиск, чтобы найти примерный результат совпадения в Excel?
Иногда нам нужно не только выполнить точный поиск, но и выполнить нечеткий поиск, как показано на скриншоте ниже. На самом деле в Excel функция «Найти и заменить» несколько помогает при нечетком поиске.
Нечеткий поиск с помощью поиска и замены
Нечеткий поиск одного или нескольких значений с помощью удобного инструмента
Образец файла
Нечеткий поиск путем поиска и замены
Предположим, у вас есть диапазон A1: B6, как показано на скриншоте ниже, вы хотите найти нечеткую строку поиска «яблоко» без учета регистра или приложения в этом диапазоне. Для выполнения задания можно применить функцию «Найти и заменить».

Искать без учета регистра
1. Выберите диапазон, который вы хотите найти, нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , введите строку, которую вы хотите найти, в Найдите текстовое поле.
2. Нажмите Параметры , чтобы развернуть диалоговое окно, снимите флажок Учитывать регистр , но установите флажок Сопоставить все содержимое ячейки .
3. Нажмите Найти все , строки перечислены без учета регистра.
Найти часть строки
1. Выберите диапазон и нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , и введите строку детали, которую вы хотите найти, в Найдите текстовое поле , снимите флажок Соответствовать всему содержимому ячейки , при необходимости также снимите флажок Учитывать регистр .
2. Нажмите Найти все , и будут перечислены ячейки, содержащие строку.
Нечеткий поиск одного значения или нескольких значений с помощью удобного инструмента
Если вам нужно найти примерно одно значение или узнать все приблизительные значения одновременно, вы можете использовать функцию Fuzzy Lookup в Kutools for Excel .
После бесплатной установки Kutools for Excel, сделайте следующее:
Найдите примерно одно значение
Предположим, вы хотите найти значение «app» в диапазоне A1: A7, но количество различных символов не может быть больше 2, а количество символов должно быть больше 1.
1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .
2. На всплывающей панели выполните следующие действия:
1) Выберите диапазон, который вы использовали для поиска, вы можете установить флажок Указано , чтобы исправить диапазон поиска.
2) Установите флажок Найти по указанному тексту .
3) Введите значение, на основе которого вы хотите выполнять нечеткий поиск, в Text .
4) Укажите необходимые критерии поиска.
3. Нажмите кнопку Найти , затем нажмите стрелку вниз, чтобы развернуть список и просмотреть результаты поиска.
Нечеткий поиск нескольких значений
Предположим, вы хотите найти все приблизительные значения в диапазоне A1: B7, вы можете сделать следующее:
1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .
2. На панели Нечеткий поиск выберите диапазон поиска, а затем укажите необходимые критерии поиска.
3. Нажмите кнопку Найти , чтобы перейти к просмотру результатов поиска, затем нажмите стрелку вниз, чтобы развернуть список.
Быстрое разделение данных на несколько листов на основе столбца или фиксированных строк в Excel
| Kutools for Excel , с более чем 300 удобными функциями, упрощает вашу работу. |
| Предположим, у вас есть рабочий лист с данными в столбцах A на G имя продавца находится в столбце A, и вам необходимо автоматически разделить эти данные на несколько листов на основе столбца A в той же книге, и каждый продавец будет разделен на новый рабочий лист. Kutools for Excel может помочь вам быстро разделить данные на несколько листов на основе выбранного столбца, как показано на скриншоте ниже в Excel. Нажмите, чтобы получить 60-дневную бесплатную пробную версию! |
| |
| Kutools for Excel: с более чем 300 удобными надстройками Excel, бесплатно и без ограничений в течение 30 дней. |
Образец файла
Щелкните, чтобы загрузить образец файла
Другие операции (статьи)
Найти наибольшее отрицательное значение (меньше 0) в Excel
Для большинства пользователей Excel найти наибольшее значение из диапазона очень легко, но как насчет поиска наибольшего отрицательного значения (меньше чем 0) из диапазона данных, смешанного с отрицательными и положительными значениями?
Найти наименьший общий знаменатель или наибольший общий знаменатель в Excel
Все мы, возможно, помним, что в студенческие годы нас просили вычислить наименьший общий знаменатель или наибольший общий знаменатель некоторых чисел. Но если их десять или больше и несколько больших чисел, эта работа будет сложной.
Пакетный поиск и замена определенного текста в гиперссылках в Excel
В Excel вы можете выполнить пакетную замену определенной текстовой строки или символа в ячейках другим с помощью функции «Найти и заменить». Однако в некоторых случаях вам может потребоваться найти и заменить определенный текст в гиперссылках, исключая другие форматы содержимого.
Примените Функция обратного поиска или поиска в Excel
Как правило, мы можем применить функцию поиска или поиска для поиска определенного текста слева направо в текстовой строке по определенному разделителю. Если вам нужно перевернуть функцию поиска, чтобы найти слово, начинающееся в конце строки, как показано на следующем снимке экрана, как вы могли бы это сделать?
Другие статьи
Инструменты повышения производительности Excel -> ->
Источник
Нечёткий текстовый поиск в Power Query
Я когда-то уже писал подробный обзор на бесплатную надстройку Fuzzy Lookup от Microsoft, позволяющую находить соответствия двух списков при неточном совпадении данных. Недавно, с последними обновлениями Office 365, аналогичный функционал пришёл и в Power Query в Excel. До Power BI Desktop, кстати, он тоже добрался.
Давайте разберёмся, как этот инструмент работает, его плюсы, минусы и нюансы применения.
Тренироваться будем на слегка модернизированном примере из прошлой статьи про надстройку Fuzzy Lookup — двух списках, которые нужно объединить в один по совпадению адресов:
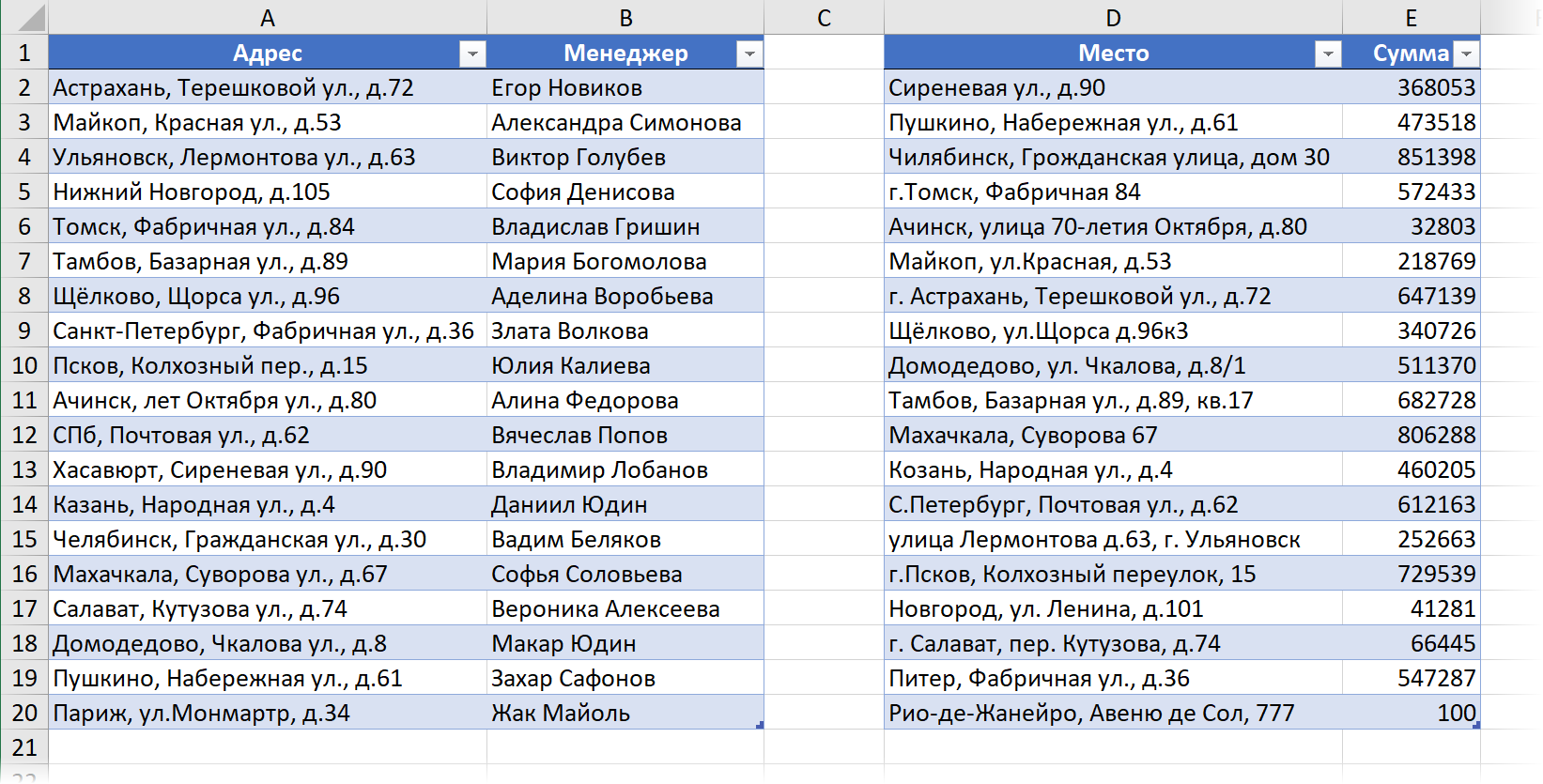
Прежде, чем начнём, обратите внимание на следующие моменты:
- Точно в этих списках совпадает только один адрес — «Пушкино, Набережная ул., д.61«. Все остальные адреса различаются с большей или меньшей степенью разброса.
- В некоторых адресах переставлены местами слова — например «Ульяновск, Лермонтова ул., д.63» и «улица Лермонтова д.63, г. Ульяновск«.
- В некоторых не хватает части данных — например, нет города в «Сиреневая ул. д.90» во второй таблице.
- Где-то город с «г.», а где-то без. С улицами — аналогично.
- Есть адреса уникальные и совершенно ни на что не похожие и ни с чем не совпадающие (Париж и Рио-де-Жанейро в конце каждого списка).
- Есть адреса с орфографическими ошибками или опечатками внутри слов (Чилябинск, Козань...)
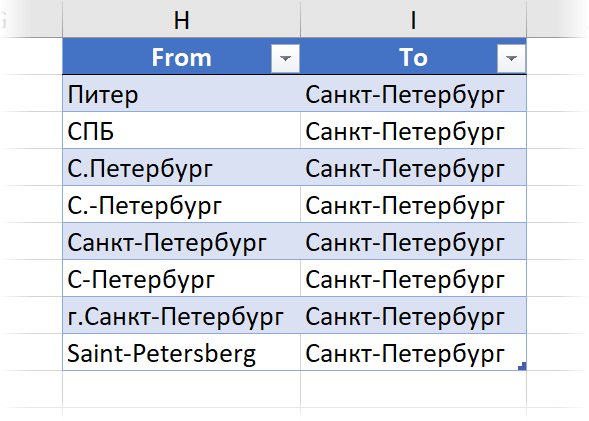
Отдельно хочу отметить проблему с Санкт-Петербургом — этот город может быть записан кучей разных способов. Чтобы учесть этот момент при связывании нам придется заранее сделать специальную таблицу преобразований. Колонки в этой таблице должны строго называться From и To и содержать все возможные варианты наименований (столбец From) и их правильные аналоги (столбец To):
Шаг 1. Грузим исходные данные в Power Query
Сначала, само-собой, нужно загрузить все наши три исходные таблицы в Power Query. Сделать это можно несколькими способами (именованный диапазон, область печати, лист целиком), но самым удобным будет, наверное, преобразование в «умные таблицы» с помощью сочетания клавиш Ctrl + T или командой Главная — Форматировать как таблицу (Home — Format as Table) .
По умолчанию, каждая умная таблица получает стандартное имя а-ля Таблица1,2. что можно, при желании изменить (но я здесь не буду).
После этого созданную «умную таблицу» можно легко залить в Power Query с помощью кнопки Из таблицы (From Table) на вкладке Данные (Data) или на вкладке Power Query (если у вас версия Excel 2010-2013 и вы установили Power Query как отдельную надстройку):
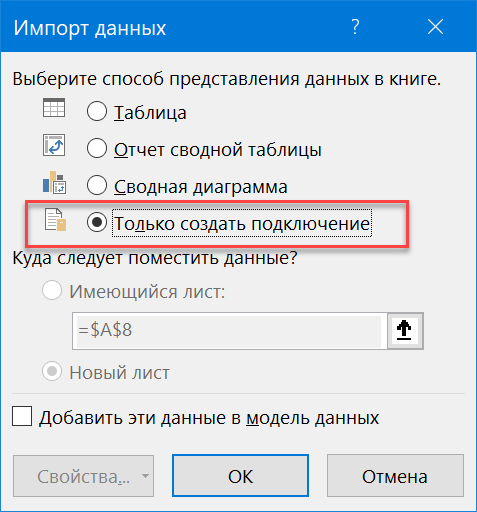
В открывшемся окне редактора запросов Power Query можно, в приципе, «допилить» наши данные при необходимости и затем сохранить полученную таблицу как подключение через Главная — Закрыть и загрузить — Закрыть и загрузить в . (Home — Close&Load — Close&Load to. ) :
И выбрать в следующем окне опцию Только создать подключение (Only create connection) :
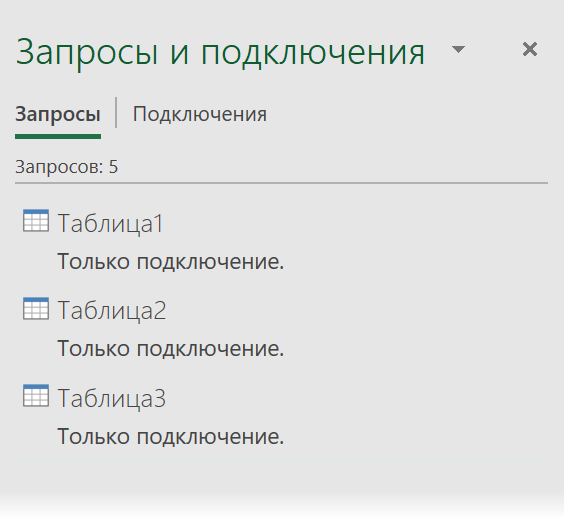
Всё это нужно по очереди проделать со всеми тремя таблицами, чтобы в итоге в правой панели запросов появились все три наши таблицы в режиме подключения:
Всё. Самая скучная часть — позади. Теперь переходим, непосредственно, к слиянию.
Шаг 2. Выполняем объединение
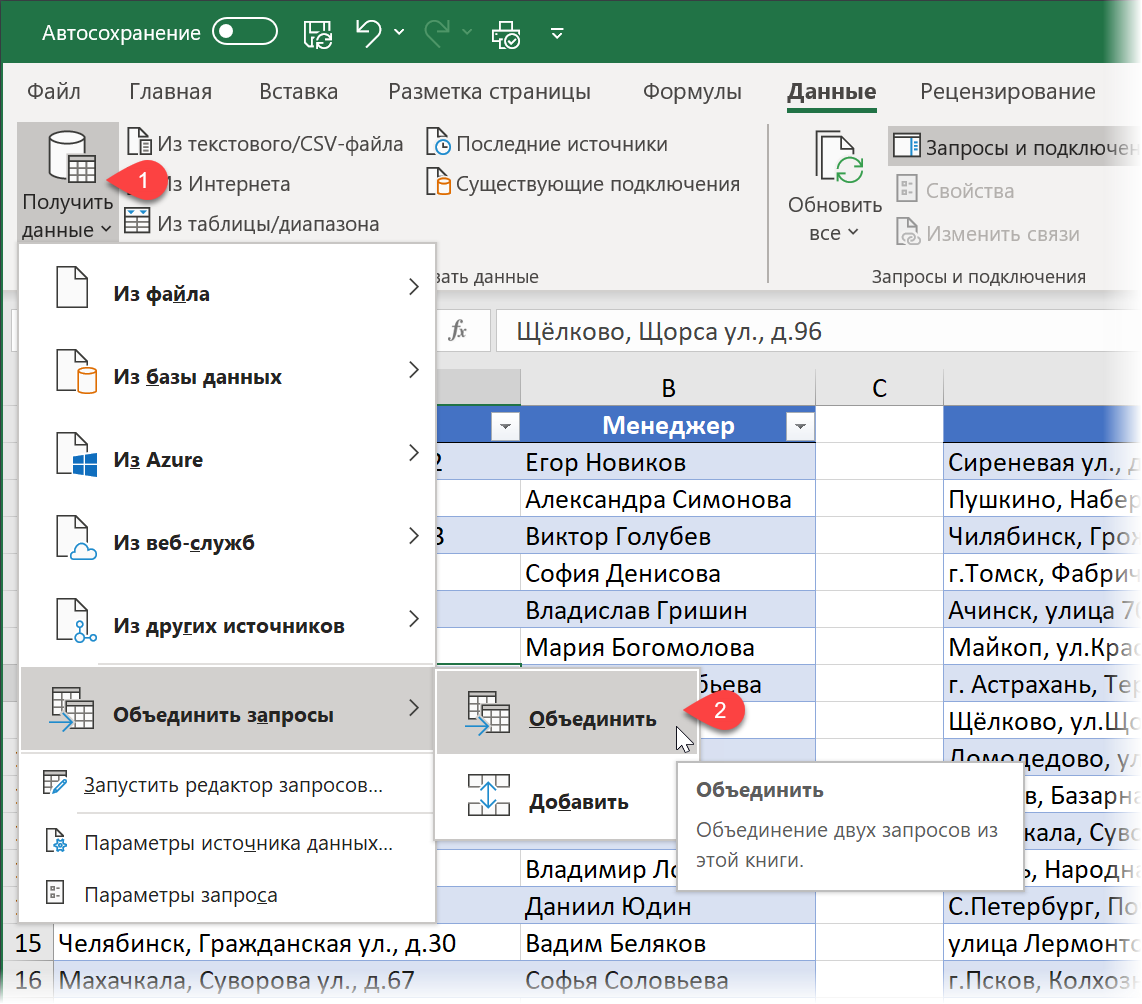
На вкладке Данные (Data) или на вкладке Power Query выбираем команду Получить данные / Создать запрос — Объединить — Объединить (Get Data / New Query — Combine queries — Merge) :
Откроется окно слияния:
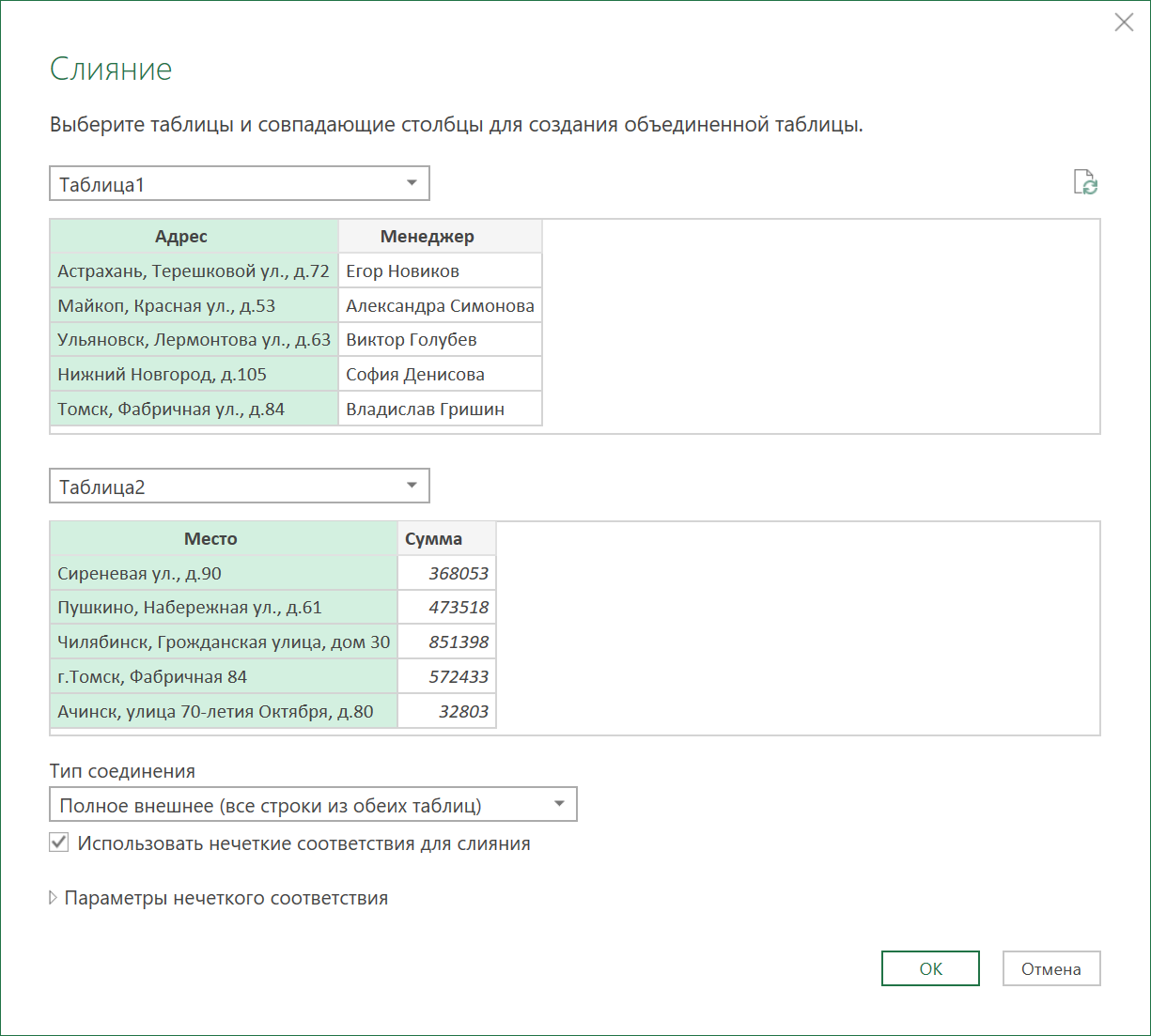
В этом окне нужно:
1. Выбрать в выпадающих списках Таблицы 1 и 2, которые мы хотим объединить.
2. Выделить в обеих таблицах столбцы, по которым мы связываем наши списки (колонки Адрес и Место, соответственно).
3. Чтобы увидеть потом не только совпадения, но и отличия и ясно понимать что именно мы нашли, а что нет — выбрать тип соединения Полное внешнее (Full Outer).
4. Включить (самое главное!) флажок Использовать нечеткие соответствия для слияния (Use fuzzy matching to perform the merge) . Именно он заставляет Power Query искать не только точные совпадения, но и приблизительные.
Под ссылкой Параметры нечеткого соответствия (Fuzzy matching options) скрывается целый блок дополнительных настроек для нечеткого слияния:

- Порог подобия (Similarity Threshold) — дробный коэффициент (от 0 до 1), определяющий, насколько строгого соответствия вы требуете при сборке. При значении этого коэффициента равном единице, Power Query будет искать, фактически, только точные совпадения. При значениях близких к нулю сильно возрастает вероятность ошибки. Имеет смысл путем 2-3 попыток подобрать максимально большое значение (т.е. максимально строгий поиск), но при котором находятся все (или большинство) результатов.
- Игнорировать регистр (Ignore case) — по умолчанию Power Query учитывает регистр при поиске, т.е. различает Москва и МОСКВА, например. Включение этого флажка позволяет избавиться от регистрочувствительности при слиянии.
- Сопоставление путем объединения текстовых фрагментов (Match by combining text parts) — в переводе на человеческий язык означает, что при поиске соответствий будет производится проверка на переставление слов внутри текста (помните Ульяновск и ул.Лермонтова?)
- Если одному адресу в первой таблице соответствуте несколько похожих адресов во второй (это особенно актуально при низких значениях порога подобия), то можно ограничить количество найденных вариантов — за это отвечает параметр Максимальное число совпадений (Maximum number of matches) .
- Чтобы учесть разные варианты написания Санкт-Петербурга — укажем нашу третью таблицу как Таблицу преобразования (Transformation Table) .
Выполнив все настройки, нажмём на ОК и развернём в появившемся окне Power Query вторую таблицу с помощью кнопки в шапке (флажок Использовать исходное имя столбца как префикс можно снять):
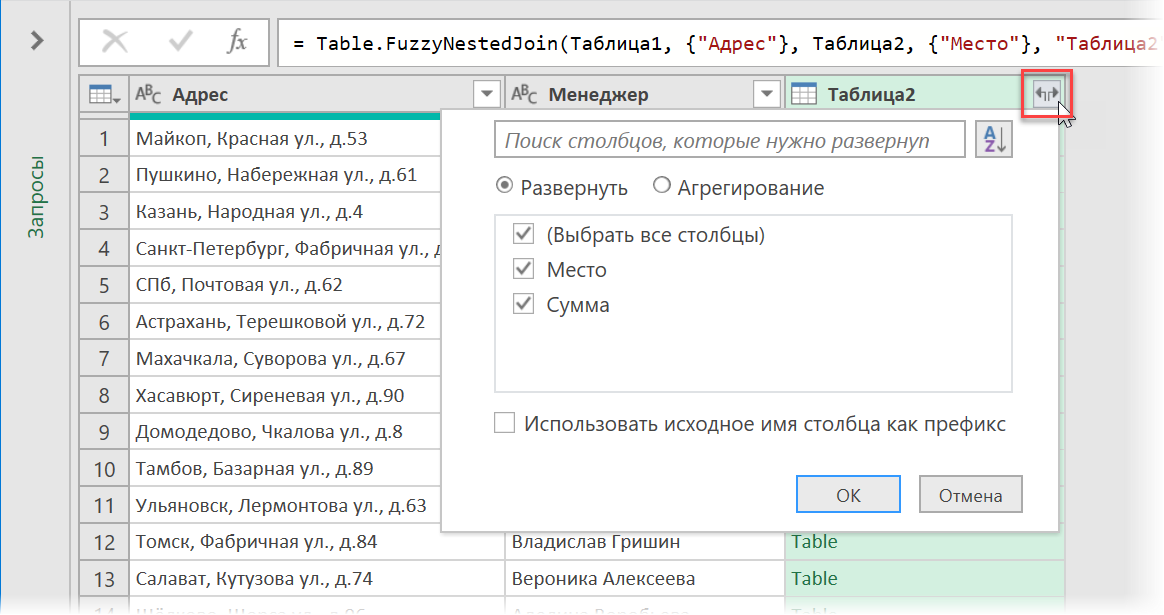
В результате получим что-то похожее на:
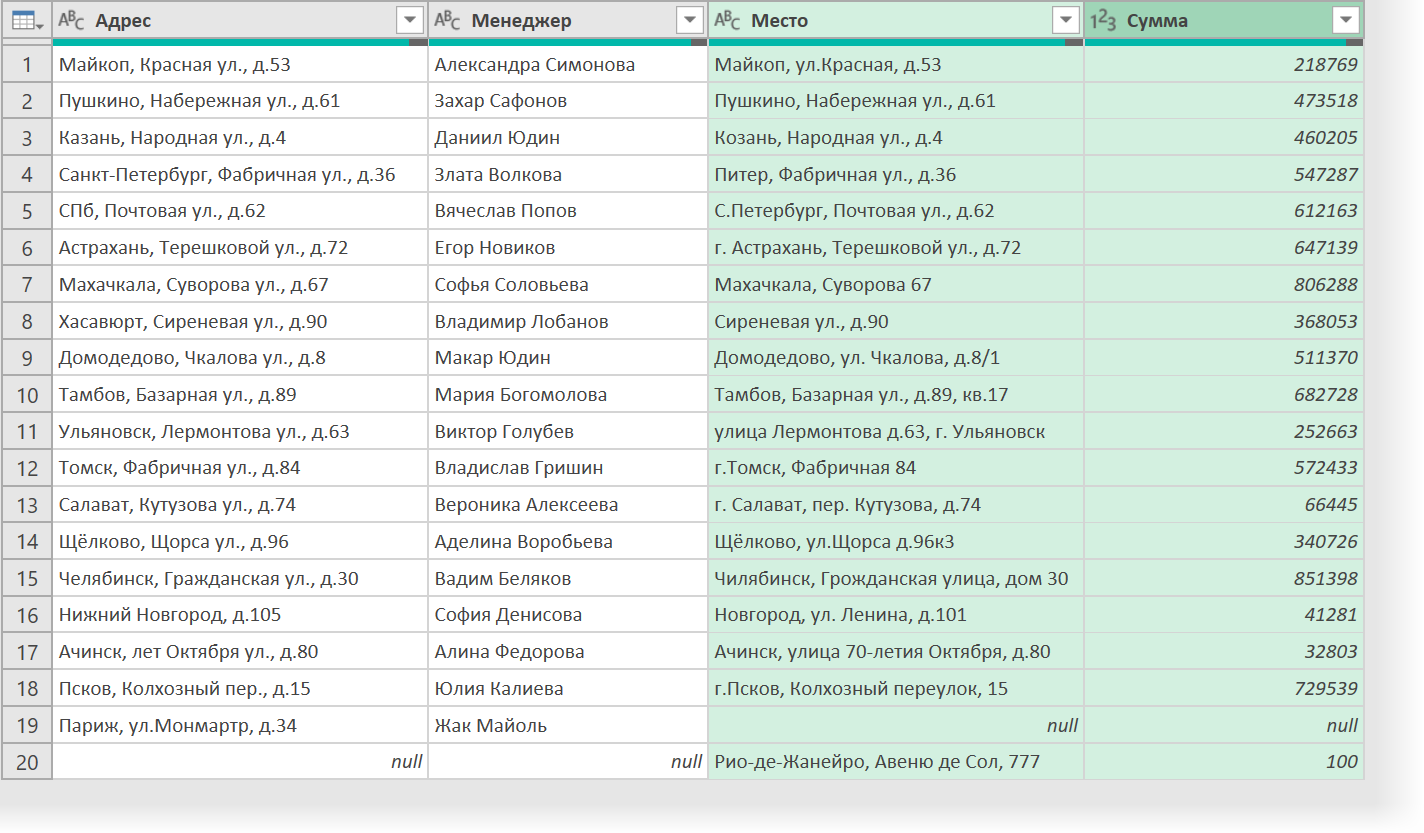
Как видите, все адреса нашли свои аналоги, кроме уникальных Парижа и Рио-де-Жанейро, в паре с которыми появились ячейки с null, т.е. пустотой.
Шаг 3. Пишем свою М-функцию подобия
В принципе, на этом можно было бы и остановиться, но, вот, лично меня во всей этой истории смущает один момент: как определить, насколько хорошо Power Query нашёл соответствие для каждого адреса? Представьте, что вам нужно объединить подобным образом таблицы по несколько тысяч строк — вероятность ошибки при таком объеме данных уже ощутимая. Как понять, где Power Query отработал нечёткое слияние хорошо (текст совпадает почти точно), а где стоит проверить совпадение вручную и, возможно, внести правки?
Вот если бы был (помечтаем!) в наших данных столбец, где указывался бы коэффициент подобия найденных адресов, наглядно иллюстрирующий точность подбора! Как бы это упростило поиск подозрительных вариантов!
К сожалению, я не нашел в Power Query встроенных инструментов для подобного 🙁 Однако, мы можем своими силами реализовать похожую штуку, написав собственную функцию подобия двух текстовых строк на встроенном в Power Query языке М (за идею огромное спасибо и поклон в пояс Андрею VG с нашего форума).
1 . На вкладке Данные выбираем команду Получить данные / Создать запрос — Из других источников — Пустой запрос (Get Data / New Query — From other sources — Blank query) .
2 . В открывшемся окне редактора запросов жмем на Главной (Home) или на вкладке Просмотр (View) кнопку Расширенный редактор (Advanced Editor) .
3 . В появившемся окне удаляем всё, что там есть по-умолчанию и копируем-вставляем туда М-код нашей функции:
Выглядеть это всё должно, в итоге, вот так:
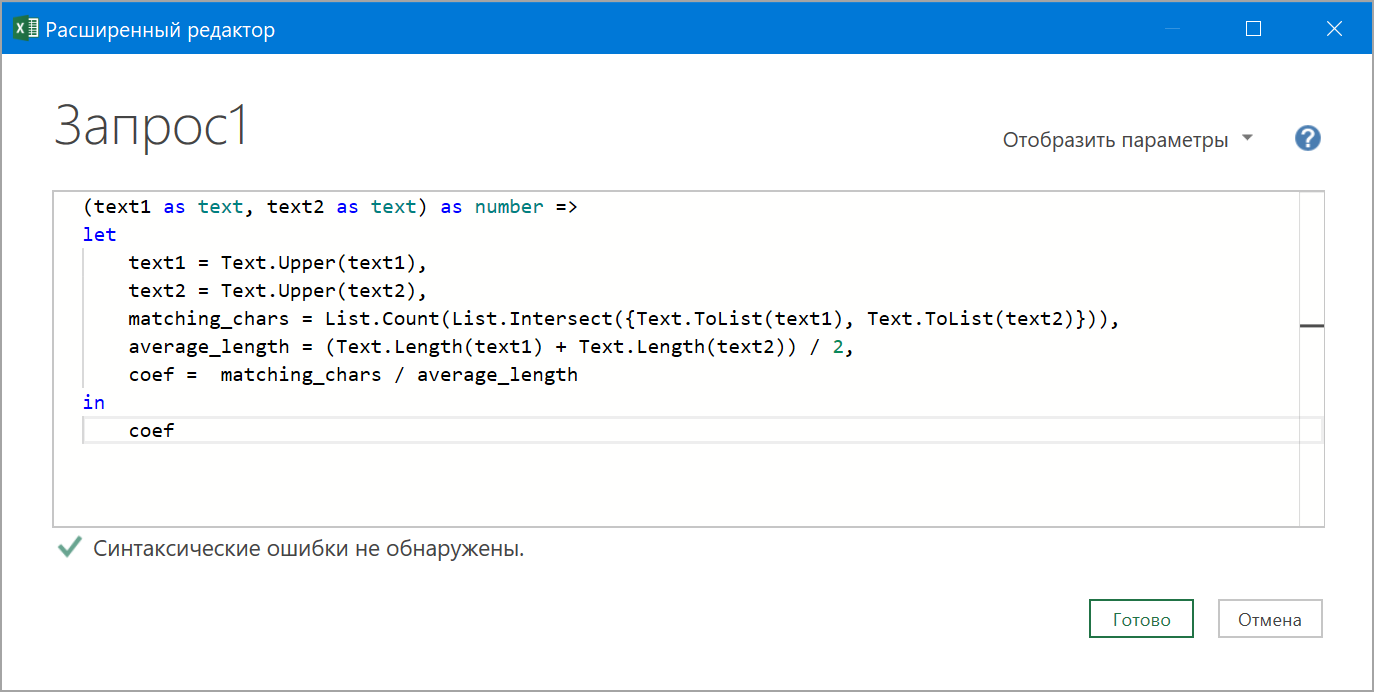
Если интересны детали, то эта функция:
- переводит обе текстовых строки в заглавные буквы функцией Text.Upper, чтобы избежать регистрочувствительности
- разбирает исходные строки на отдельные символы функциями Text.ToList
- ищет количество совпадений символов функциями List.Intersect и List.Count и помещает его в переменную matching_chars
- вычисляет среднюю длину исходных текстовых строк с помощью функций Text.Length и помещает результат в переменную average_length
- делит число совпадений на среднюю длину, чтобы получить коэффициент подобия
Само-собой, эта логика отличается от той, что использует Power Query при поиске соответствий (а как именно это делает Power Query — знают только разработчики в Microsoft). Однако, в подавляющем большинстве реальных случаев, наша функция со своей задачей отлично справляется — проверено на опыте.
После нажатия на Готово в правой панели окна Power Query можно переименовать нашу функцию, дав ей более наглядное имя (например, КоэфПодобия вместо Запрос1).
Теперь осталось применить её к нашим данным. Выберем на вкладке Добавление столбца команду Вызвать настраиваемую функцию (Add Column — Invoke Custom Function) и введём ее аргументы в открывшемся окне:
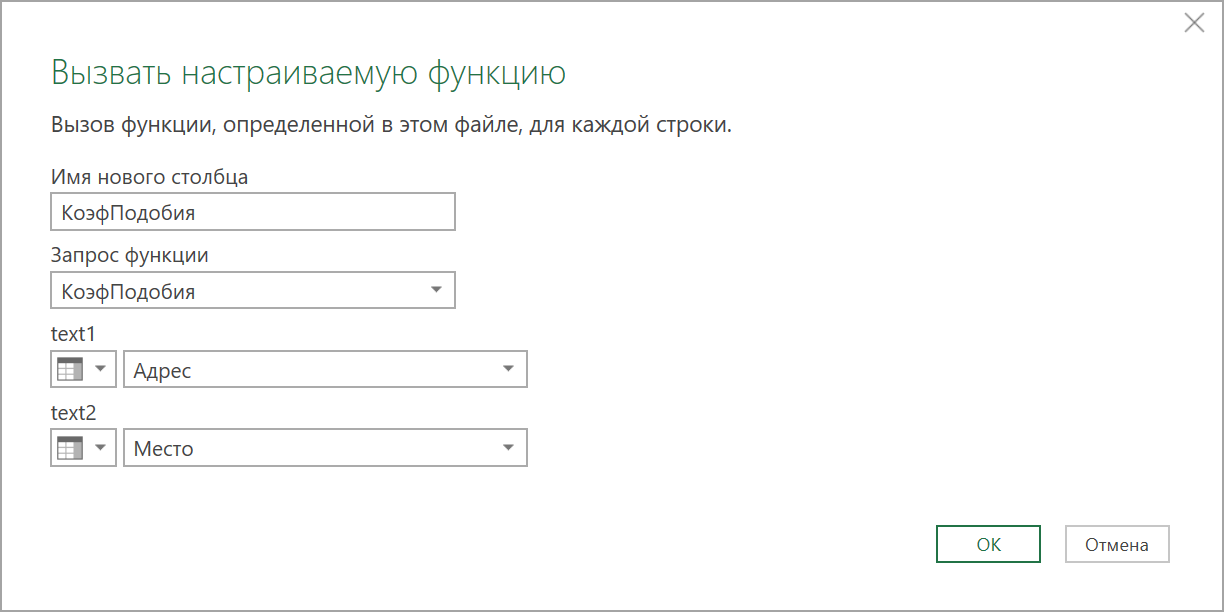
После нажатия на ОК мы, наконец, получим желаемое — столбец, где будет виден числовой коэффициент подобия, наглядно отображающий качество подбора наших адресов:
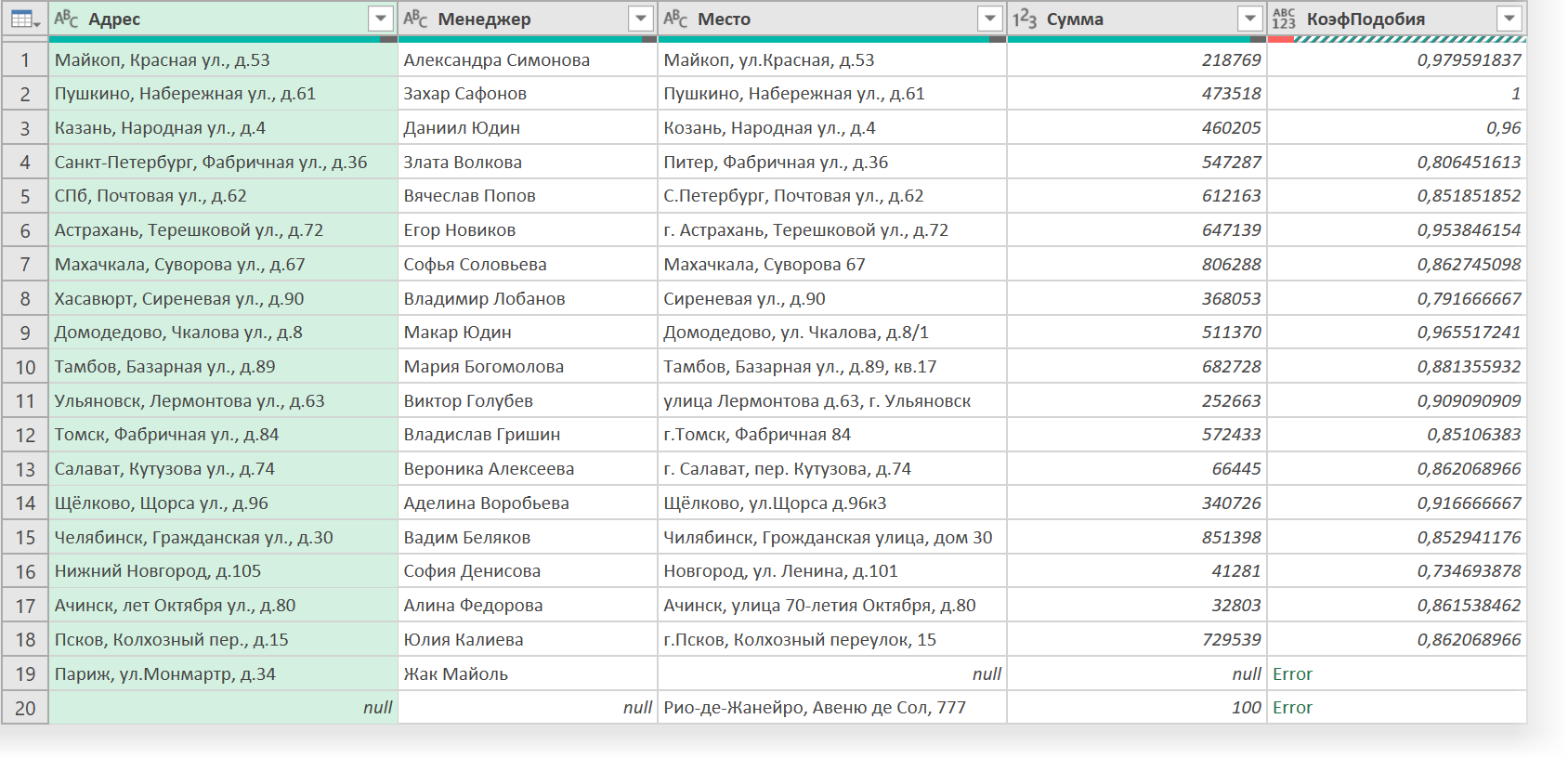
Щёлкнув правой кнопкой мыши по заголовку получившегося столбца, можно выбрать команду Заменить ошибки (Replace Errors) и легко заменить получившиеся Error в Париже и Рио-де-Жанейро на нули. Ну, а затем отсортировать нашу таблицу по убыванию по столбцу коэффициентов и выгрузить обратно в Excel уже знакомой командой Главная — Закрыть и загрузить (Home — Close&Load) :
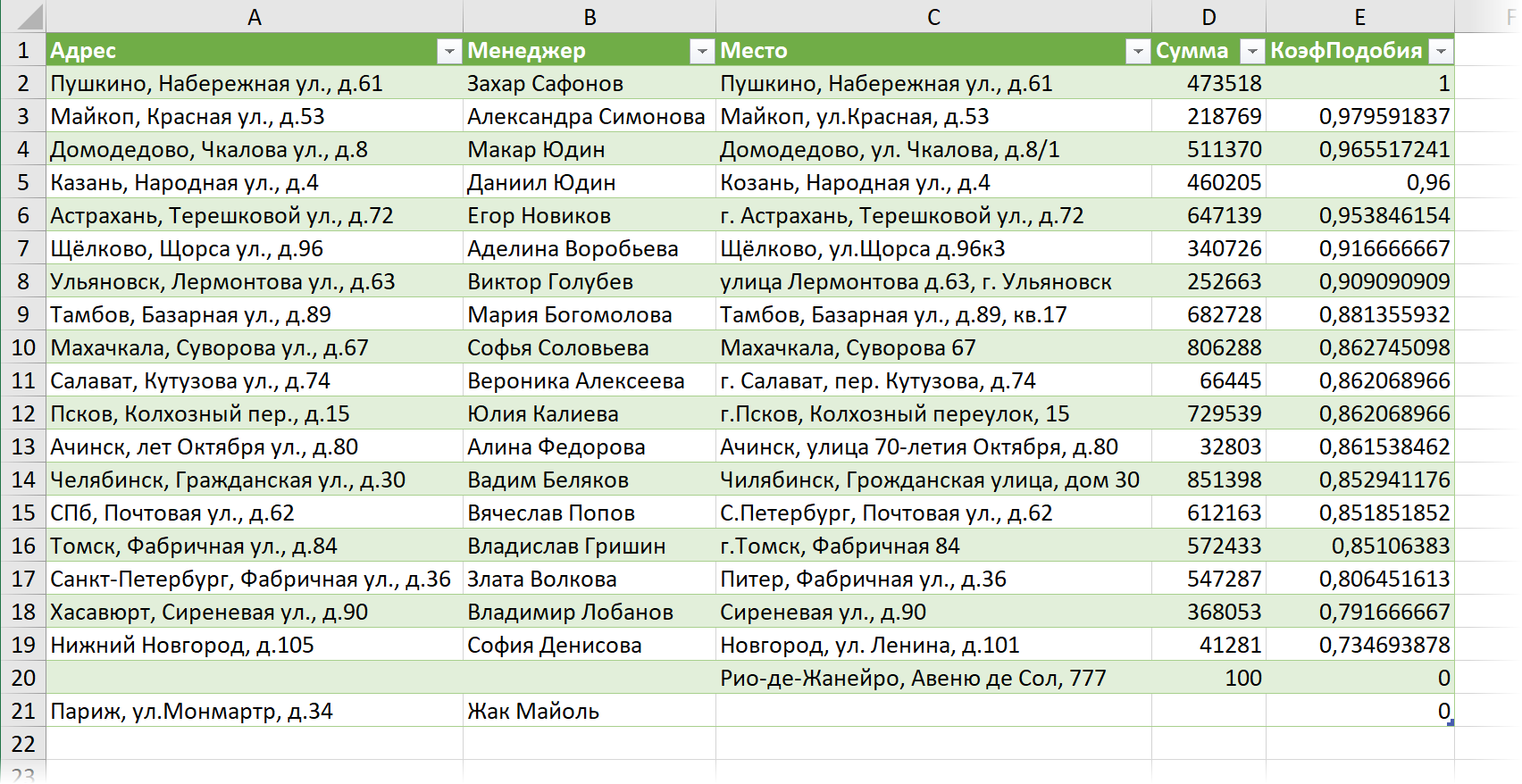
Точные совпадения в начале списка проблем не составят, а вот строки в конце списка, возможно, потребуют вашего внимания и «доработки напильником». В любом случае, такой вариант слияния мне кажется более надежным.
P.S. А у меня в Excel такого нет!
Для всех, кто после прочтения этой статьи немедленно рванёт в свой Excel проверять наличие нечёткого поиска в Power Query, ещё разок хочу уточнить:
- У вас должен быть Office 365 по подписке, а не Office 2013, 2016, 2019 и т.д. К сожалению, политика Microsoft на данный момент такова, что только подписчики Office 365 получают все последние плюшки и нововведения типа неточного поиска, динамических массивов, новой функции ВПР (ПРОСМОТРX) и т.п.
- У вас должны быть установлены все последние обновления. Имейте ввиду, что в некоторых компаниях IT-службы намеренно тормозят и откладывают установку обновлений Office, т.к. они могут нарушать функционирование других программ (связки Excel c ERP и т.п.)
- Обновления рассылаются всем пользователям Office 365 волнами в течение нескольких недель. Неточный поиск появился у меня на одном компьютере после обновлений в конце прошлого года, а на другом — уже в начале этого. Если прямо сейчас у вас ещё нет этой функции — подождите и всё будет 🙂
Источник
Еще одна проблема, которую часто приходится решать при обработке данных для последующего анализа — это сопоставление информации из разных источников. В наиболее простом случае это может быть сопоставление двух таблиц, в которых один из столбцов полностью или частично совпадают. В случае, если обработка данных проходит в СУБД, то задача решается написанием простого SQL-запроса (при условии, что исходные таблицы правильно созданы и имеют идентификаторы). В Excel для решения подобных задач существует замечательная функция ВПР (VLOOKUP), которая берет значение в одном из столбцов таблицы и возвращает значение из другого столбца.
Однако практическое использование этой функции для обработки обычных данных, может оказать довольно проблематичным. Что делать, если значения «почти» совпадают, но не совсем точно? К примеру, в одной из таблиц сравниваемая ячейка имеет запятую, а в другой нет? Или в одной используется «-«, а в другой «–» и так далее.
Я с подобными трудностями постоянно сталкиваюсь как минимум в двух случаях:
- При обработке данных по отдельным регионам РФ или странам мира. Проблема заключается в том, что разные страны или регионы могут иметь в разных источниках слегка отличающиеся названия. К примеру, » г. Москва» или «Москва (город)», «Белоруссия» или «Республика Беларусь», «Ханты-Мансийский автономный округ — Югра» или »
Ханты-Мансийский авт. округ — Югра» и так далее. Примеров может быть множество, причем зачастую один и тот же источник (тот же Росстат) может использовать в разных публикациях или разных источниках немного отличающиеся названия регионов. Формально существует ГОСТ 7.67-2003, который определяет как должны называться страны и российские регионы «по стандарту», но на практике в точности ему никто не следует даже в официальных статистических публикациях. Да и ГОСТ сам себе уже старый (2003 год) и странный. к примеру, в нем определены «Башкирия (Республика Башкортостан)», но просто «Татарстан». Почему именно так понять решительно невозможно, запомнить — тем более. Названия стран в английском языке также могут именоваться слегка по разному. Классическое «USA», «U.S.» или «United States»? - Названия видов экономической деятельности ( поОКВЭД). Формально тоже существует официальный вариант названий, выложенный на сайте Росстата. Но и сам Росстат ему не следует. К примеру, в ЦБСД названия видов деятельности часто имеют такой вид «Предоставление усл. по добыче нефти и газа» вместо «Предоставление услуг по добыче нефти и газа» (11.2) или «Добыча и произ-ство соли» вместо «Добыча и производство соли» и так далее. ЦБСД при выдаче результатов по видам экономической деятельности не сохраняет код вида, поэтому идентификация возможно только по названию. Новая информационная система — «Новая межведомственная информационно-статистическая система»- имеет одинаковые названия видов в соответствии со стандартом и даже умеет выдавать результаты в формате SDMХ, в котором присутствуют коды видов деятельности, но она обновляется с большим опозданием.
Этими примерами все не ограничивается. Подобная проблема возникает постоянно, когда нужно объединить информацию из разных источников, относящихся к одной и той же сущности, которая не имеет однозначного идентификатора.
Что же делать?
Первый и достаточно очевидный ответ — сделать все вручную. Метод вполне хороший и оправдывает себя, если количество «сущностей» не слишком велико, и задача возникает лишь эпизодически.
Если же речь о других масштабах, к примеру, раскидать данные по всем более чем двум тысячам видам деятельности и имеет регулярный характер, можно подумать об автоматизации, по крайней мере частичной.
В терминах обработки текстов подобная задача носит стандартное название «fuzzy string match». Существует множество алгоритмов для решения задач. Хорошее их описание на русском языке есть на хабрахабре. Общая идея всех алгоритмов — разработка некоторой метрики оценки «схожести» строк. Полностью одинаковые строки имеют метрику 1.0, полностью не совпадающие строки — 0.0. Пользователь задает «точку отсечения» строк, которые будут считаться одинаковыми — к примеру, это может быть 0.9 и алгоритм считает, что строки которые значение метрики больше являются одинаковыми. Один из наиболее известных метрик — расстояние Левенштейна (по имени советского математика из Института им. Келдыша). Расстояние Левенштейна определяет минимальное количество вставок, замен или удалений символов, необходимое для того, чтобы превратить одну строку в другую.
Алгоритмы — это хорошо, но как воспользоваться их возможностями без необходимости того, чтобы программировать самому?
Я знаю два бесплатных инструмента, которые можно использовать прямо «с колес» без особых знаний тонкостей алгоритмов:
- Google Refine. Как называет его сама Google, » a power tool for working with messy data». Программа бесплатно скачивается и устанавливается на десктоп. Работает в окне браузера. Позволяет открыть локальный файл или документ Google Docs и сопоставить «похожие» значения. Для нечеткого сравнения программа предлагает несколько алгоритмов, подробно описанных в документации. Вообще программа умеет много чего, и имеет смысл поразбираться в ней, благо документация написана хорошо, есть даже видеоролики с иллюстрациями разных возможностей. Проблема для меня заключается в том, что передача файлов и обратно в Google Refine занимает время. Работа в веб-браузере понятна, но не очень удобна (для меня по крайней мере), поэтому я использовал несколько раз Google Refine для обработки бюджетной статистики и обработки большой таблицы со статистикой по странам по разным странам, но не нашел программу уж очень удобной для быстрой работы.
- Надстройка Fuzzy Lookup для Excel, написанная самой Microsoft. Программа также бесплатно скачивается и устанавливается в Excel. Внешний вид выглядит примерно так (обработка таблиц с видами деятельности):
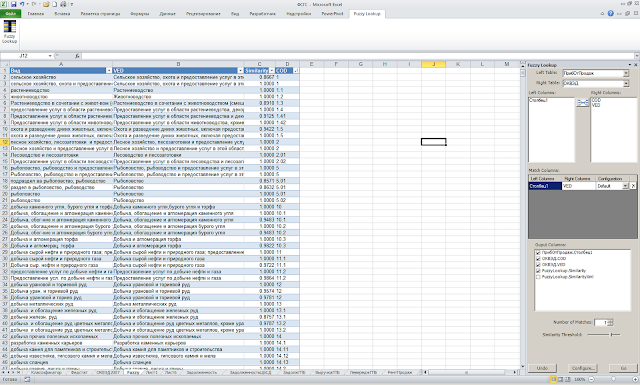
В архиве есть файл с примером, который показывает как все работает. Важное, что нужно запомнить для того, чтобы сравнивать таблицы: нужно их создать в виде «таблицы» (то есть Вставка-Таблица). Первой выбирается таблица из которой берутся исходные значения, второй — которые сопоставляются с исходными. Можно выбрать несколько столбцов, по которым будет проводиться сопоставление столбцов, для этого надо добавить несколько столбцов в Match Columns. В Output Columns можно выводить не все имеющиеся столбцы, и лишь те, что нужно. Это довольно удобно. К примеру, стандартная функция ВПР ничего подобного не умеет, поэтому надстройкой Fuzzly Lookup можно пользоваться и для «четкого» сопоставления разных таблиц.
Алгоритм работы программы не описывается, но на практике он дает вполне нормальные результаты и для строк на русском языке. Главное не забыть, проверить результаты сопоставления и исправить возможные ошибки алгоритма вручную. Для этого надо обратить на строки, в которых Fuzzy.Lookup.Similarity отличается от 1 и удостовериться, что «автоматическое» сопоставление сработало правильно.
P.S. Функция ВПР имеет параметр «Интервальный просмотр», который можно поставить на значение «1». Это будет означать приблизительное соответствие . Но я не рекомендую его использовать ни при каких обстоятельствах, так как результаты этой «приблизительности» абсолютно непонятны. Можно легко получить неправильные значения. Ошибку же крайне сложно будет обнаружить пост-фактум.
ГлавнаяНечеткий поиск в Excel — Fuzzy Lookup Add-In for Excel
Нечеткий поиск — позволяет искать нечеткие соответствия текста в нескольких источниках.
Установочник:
https://www.microsoft.com/en-us/download/confirmation.aspx?id=15011
Скинуть на лист два источника, которые нужно сравнить.





1.
2.
3.
4.
5.
6. Перед нажатием GO — нужно на листе выбрать область куда выведется результат
Иправление возможной ошибки — меняем разделитель на точку.

Иногда нам нужно не только выполнить точный поиск, но и выполнить нечеткий поиск, как показано на скриншоте ниже. На самом деле в Excel функция «Найти и заменить» несколько помогает при нечетком поиске.
Нечеткий поиск с помощью поиска и замены
Нечеткий поиск одного или нескольких значений с помощью удобного инструмента
Образец файла
Предположим, у вас есть диапазон A1: B6, как показано на скриншоте ниже, вы хотите найти нечеткую строку поиска «яблоко» без учета регистра или приложения в этом диапазоне. Для выполнения задания можно применить функцию «Найти и заменить».

Искать без учета регистра
1. Выберите диапазон, который вы хотите найти, нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , введите строку, которую вы хотите найти, в Найдите текстовое поле.

2. Нажмите Параметры , чтобы развернуть диалоговое окно, снимите флажок Учитывать регистр , но установите флажок Сопоставить все содержимое ячейки .

3. Нажмите Найти все , строки перечислены без учета регистра.

Найти часть строки
1. Выберите диапазон и нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , и введите строку детали, которую вы хотите найти, в Найдите текстовое поле , снимите флажок Соответствовать всему содержимому ячейки , при необходимости также снимите флажок Учитывать регистр .

2. Нажмите Найти все , и будут перечислены ячейки, содержащие строку.

Нечеткий поиск одного значения или нескольких значений с помощью удобного инструмента
Если вам нужно найти примерно одно значение или узнать все приблизительные значения одновременно, вы можете использовать функцию Fuzzy Lookup в Kutools for Excel .
| Kutools for Excel , с более чем 300 удобными функциями, упрощает вашу работу. |
|
Бесплатная загрузка |
После бесплатной установки Kutools for Excel, сделайте следующее:
Найдите примерно одно значение
Предположим, вы хотите найти значение «app» в диапазоне A1: A7, но количество различных символов не может быть больше 2, а количество символов должно быть больше 1.

1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .

2. На всплывающей панели выполните следующие действия:
1) Выберите диапазон, который вы использовали для поиска, вы можете установить флажок Указано , чтобы исправить диапазон поиска.
2) Установите флажок Найти по указанному тексту .
3) Введите значение, на основе которого вы хотите выполнять нечеткий поиск, в Text .
4) Укажите необходимые критерии поиска.

3. Нажмите кнопку Найти , затем нажмите стрелку вниз, чтобы развернуть список и просмотреть результаты поиска.

Нечеткий поиск нескольких значений
Предположим, вы хотите найти все приблизительные значения в диапазоне A1: B7, вы можете сделать следующее:

1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .
2. На панели Нечеткий поиск выберите диапазон поиска, а затем укажите необходимые критерии поиска.

3. Нажмите кнопку Найти , чтобы перейти к просмотру результатов поиска, затем нажмите стрелку вниз, чтобы развернуть список.

Быстрое разделение данных на несколько листов на основе столбца или фиксированных строк в Excel
|
| Предположим, у вас есть рабочий лист с данными в столбцах A на G имя продавца находится в столбце A, и вам необходимо автоматически разделить эти данные на несколько листов на основе столбца A в той же книге, и каждый продавец будет разделен на новый рабочий лист. Kutools for Excel может помочь вам быстро разделить данные на несколько листов на основе выбранного столбца, как показано на скриншоте ниже в Excel. Нажмите, чтобы получить 60-дневную бесплатную пробную версию! |
 |
| Kutools for Excel: с более чем 300 удобными надстройками Excel, бесплатно и без ограничений в течение 30 дней. |
Образец файла
Щелкните, чтобы загрузить образец файла
Другие операции (статьи)
Найти наибольшее отрицательное значение (меньше 0) в Excel
Для большинства пользователей Excel найти наибольшее значение из диапазона очень легко, но как насчет поиска наибольшего отрицательного значения (меньше чем 0) из диапазона данных, смешанного с отрицательными и положительными значениями?
Найти наименьший общий знаменатель или наибольший общий знаменатель в Excel
Все мы, возможно, помним, что в студенческие годы нас просили вычислить наименьший общий знаменатель или наибольший общий знаменатель некоторых чисел. Но если их десять или больше и несколько больших чисел, эта работа будет сложной.
Пакетный поиск и замена определенного текста в гиперссылках в Excel
В Excel вы можете выполнить пакетную замену определенной текстовой строки или символа в ячейках другим с помощью функции «Найти и заменить». Однако в некоторых случаях вам может потребоваться найти и заменить определенный текст в гиперссылках, исключая другие форматы содержимого.
Примените Функция обратного поиска или поиска в Excel
Как правило, мы можем применить функцию поиска или поиска для поиска определенного текста слева направо в текстовой строке по определенному разделителю. Если вам нужно перевернуть функцию поиска, чтобы найти слово, начинающееся в конце строки, как показано на следующем снимке экрана, как вы могли бы это сделать?
Другие статьи
Инструменты повышения производительности Excel -> ->